显式状态模型引入的新特性¶
声明式模型中的变量值是不可修改的, 这称为不变性. 在该模型中, 如果我有一个巨大的List, 想修改其最后一个元素, 声明式模型必须重新创建一个新的List以满足需求, 这在性能上明显低效.
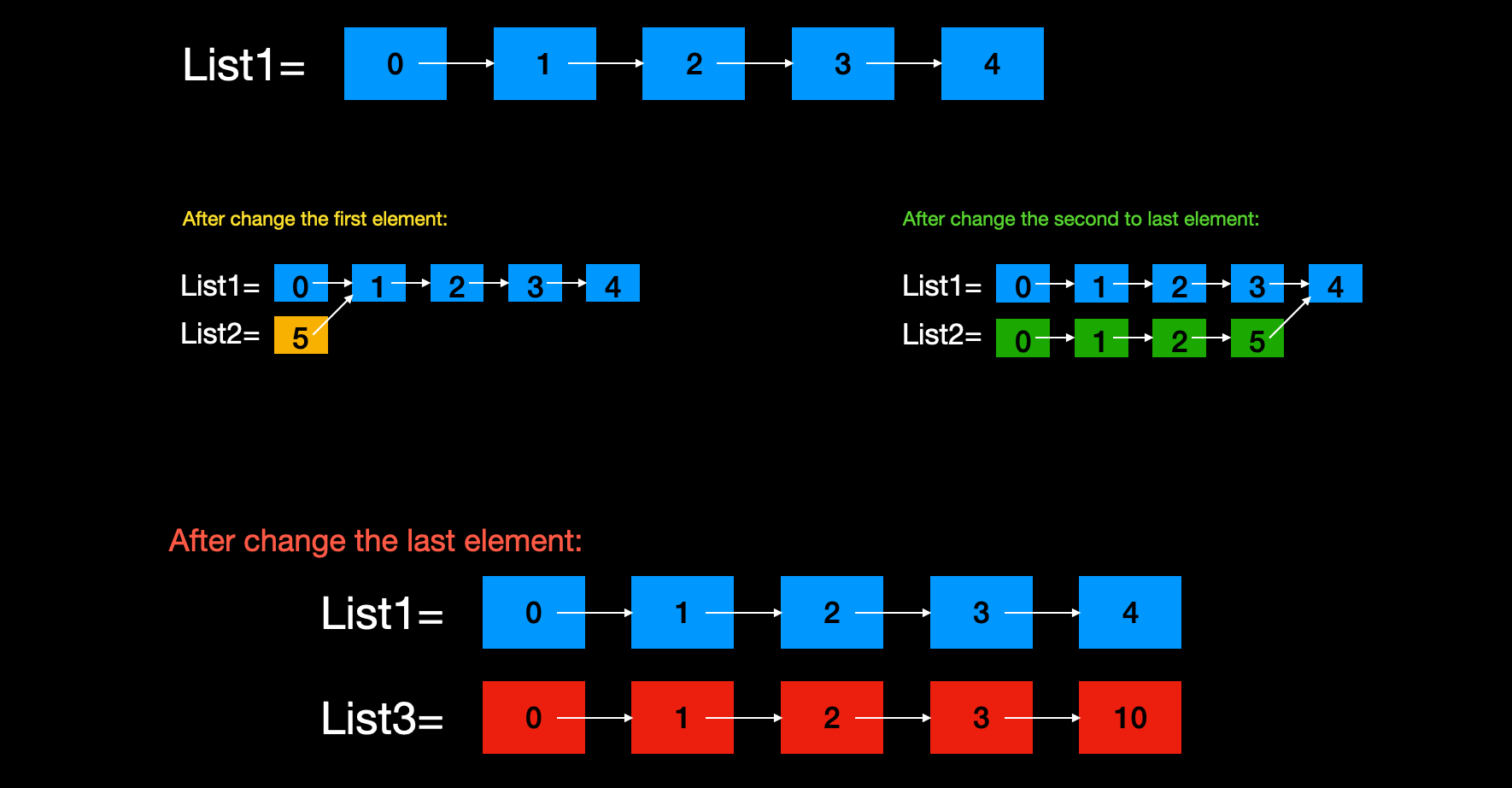
声明式模型中, list是不可变的, 修改list中的值会生成一个新的list, 声明式模型语言一般会进行优化, 让新创建的list和旧的list共享一部分数据, 以此减少开销. 然而修改最后一个元素, 声明式模型就不得不创建一个全新的list, 这开销很大.
此外, 由于缺少循环关键词, 我们不得不使用递归来替代, 这使得某些特定程序的编写变得异常困难.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24from collections import deque def bfs(graph, start): visited = set() queue = deque([start]) visited.add(start) while queue: node = queue.popleft() print(node) # do actual work here for neighbor in graph[node]: if neighbor not in visited: visited.add(neighbor) queue.append(neighbor) graph = { 'A': ['B', 'C'], 'B': ['D', 'E'], 'C': ['F'], 'D': [], 'E': [], 'F': [] } bfs(graph, 'A')
用迭代的方式实现光度优先遍历清晰且简单
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22def bfs_recursive(queue, visited, graph): if not queue: return next_queue = [] for node in queue: print(node) # do actual work here for neighbor in graph[node]: if neighbor not in visited: visited.add(neighbor) next_queue.append(neighbor) bfs_recursive(next_queue, visited, graph) graph = { 'A': ['B', 'C'], 'B': ['D', 'E'], 'C': ['F'], 'D': [], 'E': [], 'F': [] } visited = set(['A']) bfs_recursive(['A'], visited, graph)
虽然递归实现的思路和迭代的相同, 但写起来还是略微复杂
显式状态模型在声明式模型的基础上引入了“可修改的变量”这一重要特性. 这意味着我们不仅可以编写声明式代码——通过描述期望结果来编写程序, 还可以编写命令式代码——通过具体操作步骤来实现功能. 而这正是我们最常使用的语言范式. 我们使用变量来承载状态, 并且可以在循环中修改状态, 而不必仅通过递归来改变状态, 这也正是显式状态模型名称的由来.
变量在不同语言中的不同风格¶
虽然变量看起来非常简单, 但不同语言对其有十分不同的阐述.
强类型 Vs 弱类型¶
首先, 你可能会听到某种语言被称为强类型, 而另一种被称为弱类型. 这是什么意思呢? 如果一种语言是弱类型的, 意味着类型之间可以进行隐式转换, 即一种类型的值可以被当作另一种类型使用. 弱类型通常被视为一种缺点而受到批评, 而目前大多数主流语言都是强类型的.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17int main() { int a = 5; double b = 3.2; // int可以隐式转换成double double c = a + b; // OK // double不能隐式转换成int, 必须使用显式的cast // int d = b; // Error: cannot convert ‘double’ to ‘int’ without a cast int d = static_cast<int>(b); // OK, 3.2被截取成3 // int* 和 int是不能相加的 int* p = &a; // int e = p + a; // Error: invalid operands to binary expression return 0; }
c++是强类型的语言, 一些c中允许的操作在c++中是不被允许的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30#include <stdio.h> void printValue(void *ptr, char type) { switch (type) { case 'i': // int printf("Integer value: %d\n", *(int *)ptr); break; case 'f': // float printf("Float value: %.2f\n", *(float *)ptr); break; case 'c': // char printf("Char value: %c\n", *(char *)ptr); break; default: printf("Unknown type\n"); } } int main() { int i = 10; float f = 3.14f; char c = 'A'; // 什么类型在这里都可以被当成float来使用, 哪怕这会导致严重问题 printValue(&i, 'f'); printValue(&f, 'f'); printValue(&c, 'f'); return 0; }
只需要使用void*指向任何值, 就可以抹去原有类型, 然后赋值给任意其他类型的指针
静态类型 Vs 动态类型¶
变量是静态的还是动态的?
大多数静态类型语言在声明变量时需要指定类型, 在这些语言中, 变量的值可以改变, 但类型必须与变量声明的类型一致, 变量的类型是静态的.
而在大多数动态类型语言中, 变量的类型是动态的, 变量可以被赋予完全不同类型的值.
1 2 3String name; name = "John"; // name = 32; // Error
1 2 3var name; name = "Wick" name = 34; // Allowed
Pass-by-Value Vs Pass-by-Reference¶
变量作为函数参数传递时, 我们会说某些语言采用传值调用, 另一些采用传引用调用.
这意味着, 除基础类型外, 对于大多数类型, 传值调用会复制变量作为函数实参, 而传引用调用则传递变量的引用(即不复制, 传递的是变量本身)作为函数实参.
在传引用调用的语言中, 函数体内对变量的修改会直接影响原有变量.

标识符是否和值分离¶
最后, 在一门语言中, 变量的值和标识符是否分离? 这是什么意思呢? 变量的标识符即变量名.
在大多数语言中, 将变量的标识符放入表达式时, 实际上就是将变量的值放入表达式, 这一点我们已经非常习惯.
然而, 在相当一部分语言中, 变量的值和标识符是分离的. 我们不能在表达式中直接引用变量名, 而必须在变量名上进行额外的操作以得到值.
换个角度理解标识符和值的分离, 我们也可以说变量和标识符分离意味着, 在这些语言中变量是一种数据容器, 变量名意味着容器对象, 而不是其中的值, 我们需要额外的操作从容器中把值取出来.
为什么要刻意分离值和标识符? 提供类似值容器的机制有什么好处? 实际上, 这确实带来了诸多优势, 以至于大多数语言中都有类似的值容器, 例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21import java.util.concurrent.atomic.AtomicInteger; public class AtomicIntegerExample { public static void main(String[] args) { // 以下关于atomicInt的操作没有竞态条件 AtomicInteger atomicInt = new AtomicInteger(0); // Increment atomically int newValue = atomicInt.incrementAndGet(); System.out.println("After increment: " + newValue); // Add 5 atomically int updatedValue = atomicInt.addAndGet(5); System.out.println("After adding 5: " + updatedValue); // Compare and set boolean updated = atomicInt.compareAndSet(6, 10); System.out.println("Compare and set successful? " + updated); System.out.println("Current value: " + atomicInt.get()); } }
Java中的AtomicInteger, 实现整数的原子读写

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24;; 声明一个namespace (ns explicit-state-model.atom-example) ;; 定义一个validator, 让其校验传入的n是否是偶数 (defn even-validator [n] (even? n)) ;; 创造一个"atom变量" (def counter (atom 0 :validator even-validator)) ;; swap是原子化的, 并且当且仅当validator返回true时才能成功 (swap! counter + 2) ;; => 2 ;; reset也是原子化的, 这里会失败 (try (reset! counter 3) (catch IllegalStateException e (println "Validation failed:" (.getMessage e)))) ;; => Validation failed: Invalid reference state ;; 从这个atom变量中取值 @counter ;; => 2
Clojure的atom, 除了原子化读写外, 还可挂载校验函数, 只有通过校验的值才能覆盖容器内的值

1 2 3 4 5 6 7 8 9 10 11 12 13 14(ns agent-example.core) ;; 定义一个修改agent变量的值的函数, 我们一般称之为action函数 (defn increment [state] (inc state)) ;; 定义一个"agent变量" (def counter (agent 0)) ;; 把action函数发送给agent变量 (send counter increment) ;; 等待action结束 (await counter) ;; 从agent中取值 (println "Counter value:" @counter)
Clojure中的agent, 支持异步计算和赋值, 类似于其他语言中的future

1 2 3 4 5 6 7 8 9 10 11 12fn work() { // 在堆内存上新建一个变量b, 可以理解为Box能自动管理堆内存, 是rust中的"智能指针" let b = Box::new(42); // 从b中取值需要*操作符 println!("The value in the box is: {}", *b); // 在堆内存上创建一个vector let boxed_vec = Box::new(vec![1, 2, 3]); println!("The boxed vector is: {:?}", boxed_vec); } // 在work函数结束后, b和boxed_vec会自动释放
Rust中的Box和C++中的智能指针, 负责管理堆内存释放, 防止内存泄漏

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18import weakref class MyClass: def __init__(self, value): self.value = value def __repr__(self): return f"MyClass({self.value})" obj = MyClass(10) weak_obj = weakref.ref(obj) print("Original object:", obj) print("Weak reference:", weak_obj) print("Dereferenced weakref:", weak_obj()) del obj # Remove the strong reference print("After deleting obj, weakref returns:", weak_obj()) #不会报错
Python中的weakref提供弱引用, 被弱引用的对象引用计数不增加, 避免对象间互相引用导致垃圾回收困难

1 2 3 4 5 6 7 8 9 10 11 12 13 14#include <stdio.h> int main() { int arr[] = {10, 20, 30, 40, 50}; int *ptr = arr; // Pointer to the first element printf("Traversing array using pointer:\n"); for (int i = 0; i < 5; i++) { printf("Element %d: %d (address: %p)\n", i, *ptr, (void*)ptr); ptr++; // Move pointer to the next element } return 0; }
在C中, 指针本质上是一种分离值和标识符的容器, 它允许在内存空间中修改指向的地址, 避免复制值带来的开销

总之, 变量的值和标识符不分离时, 使用起来非常简单且符合直觉;而当变量的值和标识符分离时, 变量更像一个值容器, 能够在取值之外提供额外功能. 许多语言同时支持这两种机制.
引入可修改的变量后的改变¶
引入可修改变量后, 我们可以在循环中修改变量的值. 因此, for, while, loop 等循环关键词随之被引入. 为了更好地控制执行流程, continue 和 break 也被引入. 最后, try, catch, finally 被引入处理意外状态或外部系统状态引发的异常.
这些语法仅在变量可修改的情况下才具有正向效用.
什么时候引入可修改变量¶
当需要编写复杂算法, 尤其是业务相关算法时, 常常涉及复杂的嵌套循环, 甚至循环与递归的嵌套以实现业务逻辑. 这时, 就需要表现力更强的显式状态, 通过循环过程中不断修改变量值来完成任务.
此外, 当代码对性能要求较高时, 引入变量以快速修改对象中的数据也是常见且必要的做法.
在编程纪律中保持不变性¶
引入可修改变量后, 难能可贵的不变形就此被抛弃了吗? 并非如此. 表面上看, 我们在代码层面放弃了不变性, 实际上只是将不变性转移到了编程纪律中. 当语言提供了“锤子”, 我们需要靠纪律来避免伤及自身.
不变式 —— 保证迭代循环的正确性¶
Dijkstra早期提出了不变式的概念. 在算法书中, 这一概念被反复强调. 算法中的不变式可以理解为: 在算法执行过程中始终保持成立的“规则”或“条件”. 它如同贯穿始终的“隐形约束”, 帮助我们编写正确的算法.

Edsger Wybe Dijkstra, 荷兰计算机科学家, 1972图灵奖得主
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22def insertion_sort(arr): # 循环不变式: 每次迭代开始前, arr[0:i] 已经有序 for i in range(1, len(arr)): key = arr[i] # 当前待插入的元素 j = i - 1 # 已排序部分的最后一个元素索引 # 将比 key 大的元素后移 while j >= 0 and arr[j] > key: arr[j + 1] = arr[j] # 元素后移 j -= 1 # 插入 key 到正确位置 arr[j + 1] = key # 此时, arr[0:i+1] 已经有序(不变式成立) return arr # 返回排序好的数组 # 使用示例 arr = [5, 2, 4, 6, 1, 3] sorted_arr = insertion_sort(arr) print(sorted_arr) # 输出: [1, 2, 3, 4, 5, 6]
插入排序中的不变式是: “第 次迭代前, 数组的前 个元素已经有序”.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18def binary_search(arr, target): left, right = 0, len(arr) - 1 # 初始化: 搜索整个数组 while left <= right: # 只要区间存在, 就继续查找 mid = (left + right) // 2 # 取中间索引 if arr[mid] == target: return mid # 找到目标, 直接返回 elif arr[mid] < target: left = mid + 1 # 目标在右半部分, 缩小左边界 else: # arr[mid] > target right = mid - 1 # 目标在左半部分, 缩小右边界 # 此时, 目标值若存在, 必在新的区间[left, right]内(不变式成立) return -1 # 区间为空, 说明目标不存在
二分查找的不变式为“每次迭代时, 目标值若存在, 必定在当前搜索区间 [, ] 内”
不变式仅与循环相关. 在循环过程中, 我们虽然修改了变量的值, 但总体目标是确保不变式始终成立.
在实现算法时, 找到一个恰当的不变式往往是正确实现算法的关键. 随着算法经验的积累, 寻找不变式的能力也会相应提升. .
声明式的API设计¶
另外, 虽然在具体实现上, 我们放弃了不变性, 但是在API设计上, 我们仍旧可以设计一些声明式的API作为模块的入口. 比较以下两种设计.
在处理简单的问题时, 无状态的API要比有状态的API更加灵活.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20# 无状态API def traffic_light(state, action): if state == "red" and action == "timer_expired": return "green" elif state == "green" and action == "timer_expired": return "yellow" elif state == "yellow" and action == "timer_expired": return "red" else: return state # invalid state transform # 显式管理状态 current_state = "red" print(current_state) # output: red current_state = traffic_light(current_state, "timer_expired") print(current_state) # output: green current_state = traffic_light(current_state, "timer_expired") print(current_state) # output: yellow
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22class TrafficLight: def __init__(self): self.state = "red" # 初始状态 def update(self, action): if self.state == "red" and action == "timer_expired": self.state = "green" # 修改状态 elif self.state == "green" and action == "timer_expired": self.state = "yellow" # 修改状态 elif self.state == "yellow" and action == "timer_expired": self.state = "red" # 修改状态 return self.state # 返回新状态 # 使用示例 light = TrafficLight() print(light.state) # 输出: red light.update("timer_expired") print(light.state) # 输出: green light.update("timer_expired") print(light.state) # 输出: yellow