现在我们要从显式状态模型继续前进. 第一站, 如何让其支持并发.
变量可修改时并发会导致什么问题¶
当变量不可修改时, 不同线程操作同一变量不会产生“读写竞争”或“写写竞争”, 因为变量是只读的. 这也是声明式并发模型简单的原因.
而当变量可修改时, 情况则截然不同.

多个线程可能同时读写同一变量, 而变量的读写在机器指令级别并非原子操作, a++可能意味着3条机器指令或更多
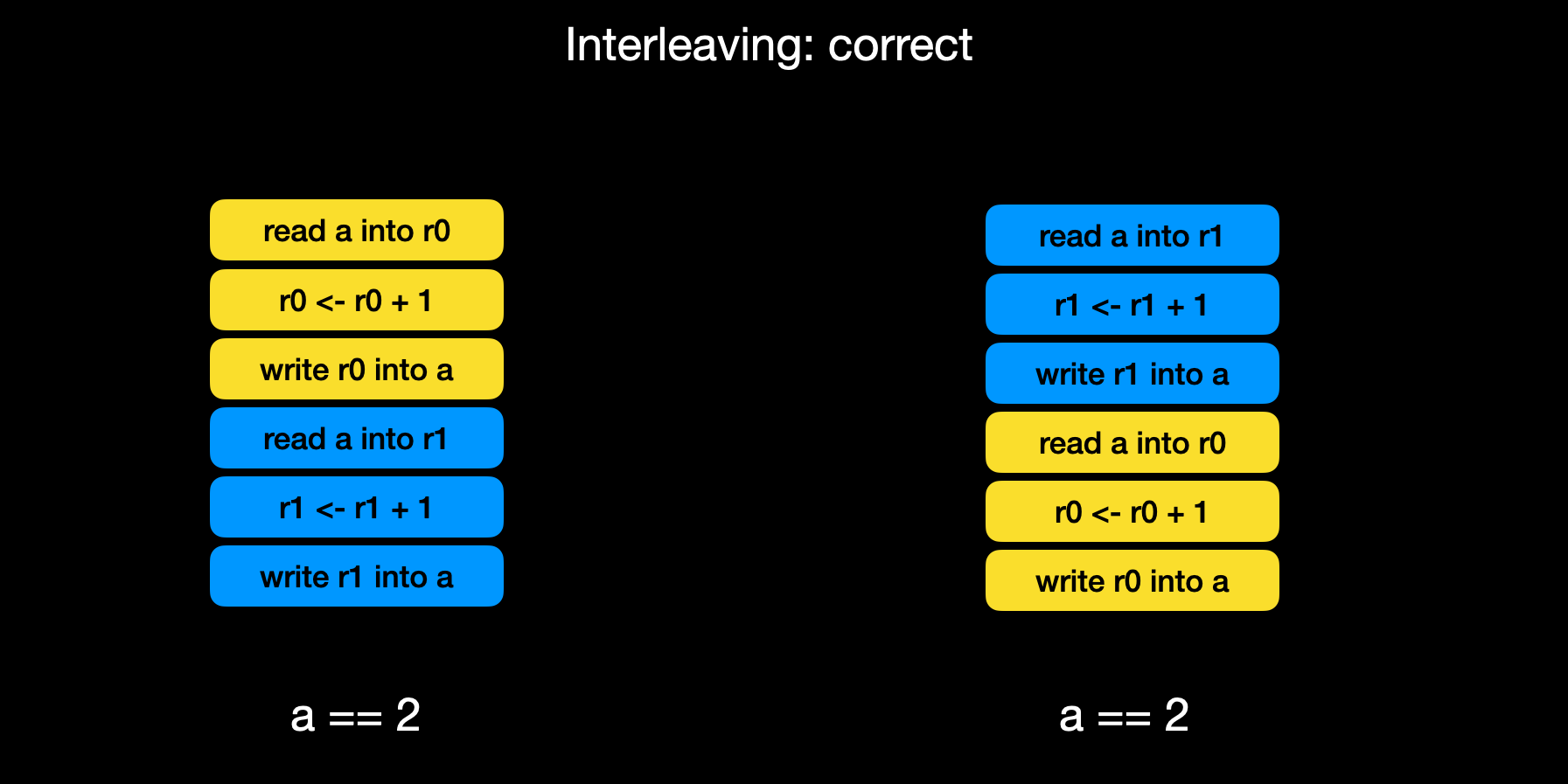
如果运行是指令执行顺序碰巧是这样的, 就能得到正确的结果
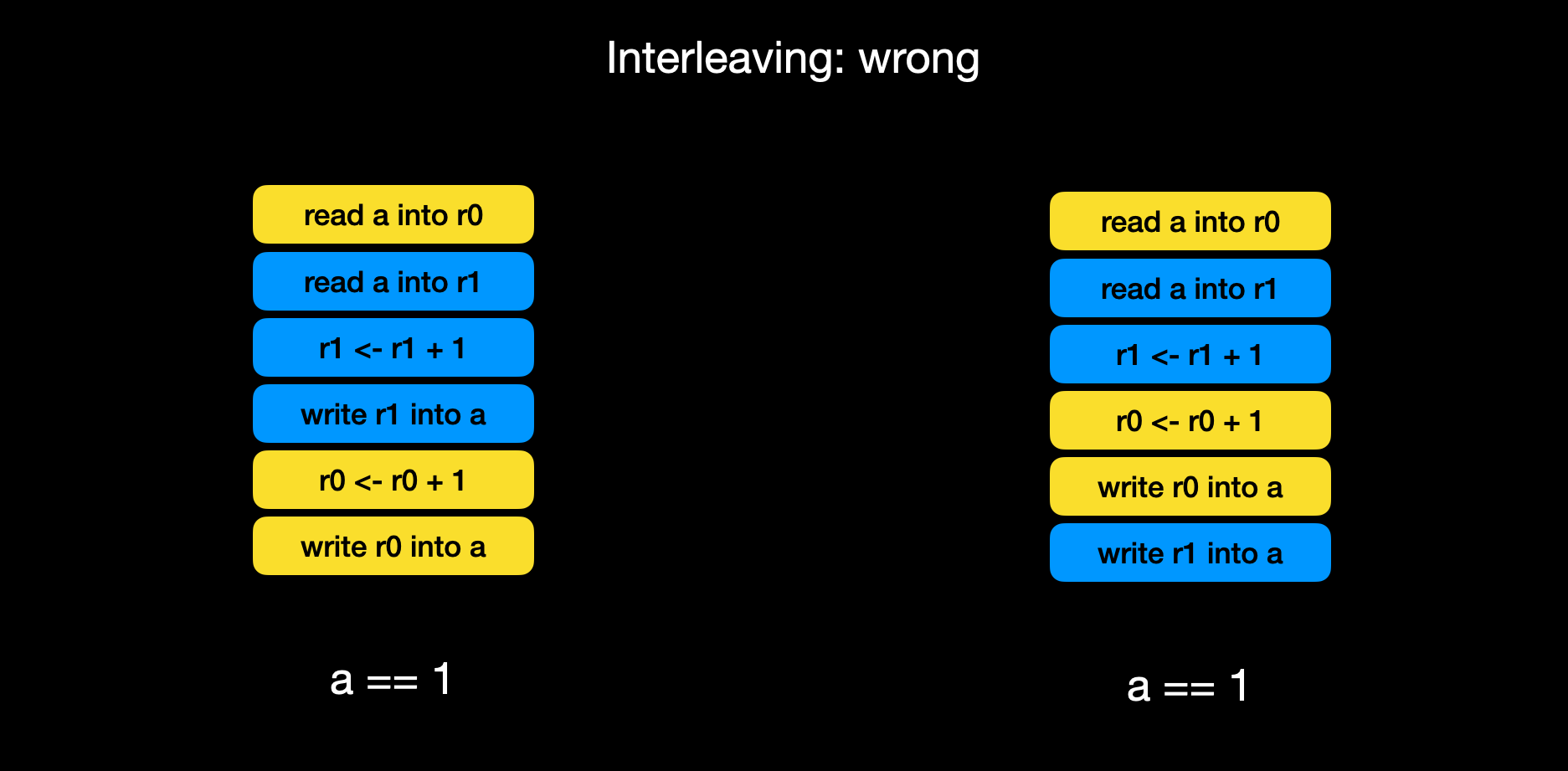
如果运行是指令执行顺序碰巧是这样的, 结果就是错误的, 而我们无法保证每一次运行时指令是怎样交织在一起的
因此, 在不做任何干预的情况下, 不同线程同时写变量可能导致数据错误, 同理, 不同线程同时读写也可能读取到脏数据.
变量对每个线程都可见, 因此这种模型也被称为共享内存模型. 共享内存模型的主要目标有两个:
- 在同类线程竞争操作同一组状态(变量)的时候, 保证其正确性.
- 通过共享内存的方式, 让线程之间可以协作完成任务.
状态并发模型引入的新概念¶
共享内存模型引入了两个新概念: lock和condition variable.
下文中, 我们只需要专注在lock和condition variable两个概念上.
- lock防止竞争读写同一块内存导致的错误
- condition variable让线程可以主动休眠和恢复, 以达到协同的目的
防止竞争读写导致的错误¶
一条语句可能对应多条机器指令, 而从程序的角度来看, 系统如何调度线程是不可知的, 具体执行时指令会交织穿插. 在所有可能的交织中, 存在一些错误的情况. 如果能够让错误的情况不发生, 就能保证并发的正确性.
那么, 如何避免这些错误的发生呢? 我们有两种策略:
预防错误情况的发生在错误发生时进行补救
策略1: 使用lock防止错误case的发生¶
我们使用lock去防止错误的case发生.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16import java.util.concurrent.locks.Lock; import java.util.concurrent.locks.ReentrantLock; public class SimpleExplicitLock { private Lock lock = new ReentrantLock(); public void accessResource() { lock.lock(); try { // do actual work here } finally { lock.unlock(); // 保证unlock会执行 } } }
java中, 如果临界区中的代码有可能报错退出, 我们需要catch错误, 并在final中进行unlock
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25package main import ( "fmt" "sync" ) var count int var lock sync.Mutex func Increment() { lock.Lock() defer lock.Unlock() // 即使后续代码报错, unlock也会执行 count++ fmt.Printf("Incrementing: %d\n", count) } func Decrement() { lock.Lock() defer lock.Unlock() count-- fmt.Printf("Decrementing: %d\n", count) }
golang中提供了defer关键词, 可以在函数正常或异常退出时执行unlock操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16#include <mutex> std::mutex mtx; void foo() { std::lock_guard<std::mutex> lock(mtx); // 声明时即获取锁 // do the work return; // 在离开foo时, 隐式释放锁, 这是RAII风格的锁 } std::mutex mtx1, mtx2; void bar() { // 一次性在多个互斥量上加锁, 类似于一次性获取多个锁. std::scoped_lock lock(mtx1, mtx2); // do the work return; // 在离开bar时, 隐式释放所有锁 }
c++11提供的lock_guard和scoped_lock, 在退出当前scope的时候自动执行unlock. (RAII风格)
lock和unlock是原子操作, 使用时一定成对出现. 无论显式(如java)还是隐式(如c++).
lock非常的简单, 但是同时也存在一些硬伤.
硬伤1: 不可重入(同一个线程两次lock会死锁)¶
原始的lock存在一个明显缺陷: 同一线程对同一个锁执行多次lock操作会导致死锁. 在日常应用中, 这种情况很常见, 例如在临界区内调用了另一个函数, 而该函数同样需要使用该锁. 此时, 一旦调用该函数, 就相当于同一线程重复获取锁, 进而引发死锁. 为了解决这一问题, 引入了更高级的锁——重入锁(reentrant lock), 也称递归互斥锁(recursive_mutex), 它允许同一线程多次加锁而不会导致死锁.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34import java.util.concurrent.locks.ReentrantLock; public class ReentrantLockExample { private final ReentrantLock lock = new ReentrantLock(); public void caller() { lock.lock(); try { System.err.println("caller: lock acquired"); callee(); // 在临界区中调用另一个方法, 但是这个方法也要获取锁 // 使用普通的lock会死锁, 但是使用ReentrantLock就不会死锁 } finally { lock.unlock(); System.err.println("caller: lock released"); } } public void callee() { lock.lock(); try { System.err.println("callee: lock acquired"); } finally { lock.unlock(); System.err.println("callee: lock released"); } } public static void main(String[] args) { ReentrantLockExample obj = new ReentrantLockExample(); obj.caller(); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21#include <iostream> #include <mutex> #include <thread> std::recursive_mutex mtx; void recursiveFunction(int depth) { // unique_lock是比lock_guard更为高级, 更为灵活的API, recursive_mutex保证了它可重入的特性 std::unique_lock<std::recursive_mutex> lock(mtx); std::cout << "Depth: " << depth << ", Thread ID: " << std::this_thread::get_id() << "\n"; if (depth > 0) { recursiveFunction(depth - 1); } } int main() { std::thread t1(recursiveFunction, 3); t1.join(); return 0; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24fun {NewLock} Token = {NewCell unit} ThreadHoldLock = {NewCell unit} proc {Lock P} if {Thread.this} == @ThreadHoldLock then % 如果当前线程就是持有锁的线程, 则直接执行 {P} else Old New in % 否则, 尝试获取锁 {Exchange Token Old New} {Wait Old} % 当Old被绑定, Wait就不在阻塞, 意味着已经获取了锁 ThreadHoldLock := {Thread.this} try {P} finally ThreadHoldLock := unit New = unit % 当New被绑定(即其他线程中的Old被绑定), 意味着已经释放了锁 end end end in `lock`(`lock`: Lock) % 返回Lock这个proc end
硬伤2: 性能问题¶
原始的lock还会带来性能问题.
如果有些线程执行读操作, 有些线程执行写操作, 彼此互斥是合理的;但如果两个线程都是读操作, 彼此还互斥则没有必要. 我们只需保证读写互斥和写写互斥即可.
这引入了另一种更高级的锁——可重入读写锁. 这种锁提升了读操作的性能, 适用于读多写少的场景.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37import java.util.concurrent.locks.ReadWriteLock; import java.util.concurrent.locks.ReentrantReadWriteLock; public class BookInfo { private double price1; private double price2; private ReadWriteLock lock; public BookInfo() { price1 = 0.0; price2 = 0.0; lock = new ReentrantReadWriteLock(); } public double getPrice1() { lock.readLock().lock(); // 读锁之间是不不互斥的, 读写和写写之间是互斥的 double val = price1; System.err.println("price1=" + val); lock.readLock().unlock(); return val; } public double getPrice2() { lock.readLock().lock(); double val = price2; System.err.println("price2=" + val); lock.readLock().unlock(); return val; } public void setPrice(double p1, double p2) { lock.writeLock().lock(); this.price1 = p1; this.price2 = p2; lock.writeLock().unlock(); } }
硬伤3: 死锁¶
最后是死锁问题.
死锁问题已经被研究多年, 已成为老生常谈. 死锁通常发生在多线程同时获取多个锁的场景中. 解决死锁同样有两种策略: 预防和补救.
| 防止死锁 | 死锁后补救 |
|---|---|
| 按照一定顺序依次获取锁 | 锁会超时 |
| 一次性获取所有锁 | 锁能够被高优先级线程抢占 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34import threading # 如果我们有多个锁 locks = [threading.Lock() for _ in range(5)] def acquire_locks_in_order(lock_list): # 在获取锁之前先按照id给它们排序, 如此一来我们就是按照固定顺序在获取锁 sorted_locks = sorted(lock_list, key=id) for lock in sorted_locks: lock.acquire() def release_locks_in_order(lock_list): # 释放锁的时候, 也先排序, 但是顺序和获取锁时*相反*. sorted_locks = sorted(lock_list, key=id, reverse=True) for lock in sorted_locks: lock.release() def task(locks_to_acquire): acquire_locks_in_order(locks_to_acquire) try: print(f"Thread {threading.current_thread().name} acquired locks") finally: release_locks_in_order(locks_to_acquire) print(f"Thread {threading.current_thread().name} released locks") # example t1 = threading.Thread(target=task, args=([locks[1], locks[3]],), name='T1') t2 = threading.Thread(target=task, args=([locks[3], locks[4]],), name='T2') t1.start() t2.start() t1.join() t2.join()
按照固定顺序获取锁, 这是最简单的方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80#include <iostream> #include <thread> #include <mutex> #include <vector> #include <algorithm> #include <chrono> class MultiLock { public: explicit MultiLock(std::vector<std::mutex*>& locks) { m_locks = locks; } void lock_all() { while (true) { if (try_lock_all()) { return; } unlock_all(); std::this_thread::sleep_for(std::chrono::milliseconds(10)); } } void unlock_all() { for (auto it = m_acquired.rbegin(); it != m_acquired.rend(); ++it) { (*it)->unlock(); } m_acquired.clear(); } private: std::vector<std::mutex*> m_locks; std::vector<std::mutex*> m_acquired; bool try_lock_all() { m_acquired.clear(); for (auto& mtx : m_locks) { if (mtx->try_lock()) { m_acquired.push_back(mtx); } else { // 有一个锁没有获取成功, 释放所有已经获取的锁(全有或全无策略) for (auto it = m_acquired.rbegin(); it != m_acquired.rend(); ++it) { (*it)->unlock(); } m_acquired.clear(); return false; } } return true; } }; void task(std::vector<std::mutex*>& locks, int id) { MultiLock multiLock(locks); multiLock.lock_all(); std::cout << "Thread " << id << " acquired all locks\n"; // Critical section std::this_thread::sleep_for(std::chrono::milliseconds(500)); multiLock.unlock_all(); std::cout << "Thread " << id << " released all locks\n"; } int main() { std::mutex m1, m2, m3; std::vector<std::mutex*> locks1 = {&m1, &m2}; std::vector<std::mutex*> locks2 = {&m2, &m3}; std::thread t1(task, std::ref(locks1), 1); std::thread t2(task, std::ref(locks2), 2); t1.join(); t2.join(); return 0; }
一次性尝试获取所有锁(try_lock), 如果有任一锁获取失败, 则释放已获取的锁并重新尝试, 这样可以保证一次性获取所有锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84#include <iostream> #include <thread> #include <mutex> #include <vector> #include <algorithm> #include <chrono> class MultiLockWithTimeout { public: explicit MultiLockWithTimeout(std::vector<std::timed_mutex*>& locks) { m_locks = locks; } bool lock_all_for(std::chrono::milliseconds timeout) { auto start = std::chrono::steady_clock::now(); m_acquired.clear(); for (auto& mtx : m_locks) { auto now = std::chrono::steady_clock::now(); auto elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(now - start); if (elapsed >= timeout) { unlock_all(); return false; // timeout expired } auto remaining = timeout - elapsed; // try_lock_for设置超时时间, 如果超时就返回false if (mtx->try_lock_for(remaining)) { m_acquired.push_back(mtx); } else { unlock_all(); return false; } } return true; } void unlock_all() { for (auto it = m_acquired.rbegin(); it != m_acquired.rend(); ++it) { (*it)->unlock(); } m_acquired.clear(); } private: std::vector<std::timed_mutex*> m_locks; std::vector<std::timed_mutex*> m_acquired; }; void task(std::vector<std::timed_mutex*>& locks, int id) { MultiLockWithTimeout multiLock(locks); while (true) { if (multiLock.lock_all_for(std::chrono::milliseconds(200))) { std::cout << "Thread " << id << " acquired all locks\n"; // Critical section std::this_thread::sleep_for(std::chrono::milliseconds(500)); multiLock.unlock_all(); std::cout << "Thread " << id << " released all locks\n"; break; } else { std::cout << "Thread " << id << " failed to acquire all locks, retrying...\n"; std::this_thread::sleep_for(std::chrono::milliseconds(50)); } } } int main() { std::timed_mutex m1, m2, m3; std::vector<std::timed_mutex*> locks1 = { &m1, &m2 }; std::vector<std::timed_mutex*> locks2 = { &m2, &m3 }; std::thread t1(task, std::ref(locks1), 1); std::thread t2(task, std::ref(locks2), 2); t1.join(); t2.join(); return 0; }
为锁设置过期时间, 超时后自动释放锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74import threading import time class PreemptableLock: def __init__(self): self._lock = threading.Lock() self.owner = None self.owner_priority = -1 self.condition = threading.Condition() def acquire(self, priority): with self.condition: current = threading.current_thread() while True: if self.owner is None: # Lock还没有被获取 self._lock.acquire() self.owner = current self.owner_priority = priority return True elif priority > self.owner_priority: # Lock可以被抢占 print(f"{current.name} (priority {priority}) preempting {self.owner.name} (priority {self.owner_priority})") self._force_release_owner() self._lock.acquire() self.owner = current self.owner_priority = priority return True else: # 模拟被阻塞 self.condition.wait() def _force_release_owner(self): # WARNING: python中锁不能被其他线程强制release # 如果要切实实现可抢占锁, 需要操作系统级别的支持, 这里只是个示例实现, 并不能用在实际系统中. print(f"Preempting {self.owner.name}") self.owner = None self.owner_priority = -1 self._lock.release() self.condition.notify_all() def release(self): with self.condition: current = threading.current_thread() if self.owner == current: self.owner = None self.owner_priority = -1 self._lock.release() self.condition.notify_all() else: raise RuntimeError("Cannot release lock not owned by current thread") def worker(lock, priority, work_time): thread_name = threading.current_thread().name print(f"{thread_name} with priority {priority} trying to acquire lock") lock.acquire(priority) print(f"{thread_name} acquired lock") time.sleep(work_time) print(f"{thread_name} releasing lock") lock.release() if __name__ == "__main__": lock = PreemptableLock() t1 = threading.Thread(target=worker, args=(lock, 1, 5), name="LowPriorityThread") # 更高优先级的线程尝试抢占锁 t2 = threading.Thread(target=worker, args=(lock, 10, 1), name="HighPriorityThread") t1.start() time.sleep(1) t2.start() t1.join() t2.join()
使锁支持抢占机制, 引入优先级概念. 当高优先级线程申请锁时, 持有锁的低优先级线程会报错并释放锁
(选读)锁的推广: 分布式锁¶
锁是语言中的一种特性, 其核心理念是互斥. 即使语言本身不提供锁, 我们也可以自行实现这一机制.
例如分布式锁: 当多个不同机器上的线程需要互斥执行某操作时, 可以通过自行实现分布式锁来保证互斥.
首先, 需要找到能够实现原子读写变量的机制, 比如在Redis中设置一个名为“resource”的整数键, 该整数可以是每个线程独有的某种ID. 由于Redis是单线程服务, 能够线性处理每个请求, 从而保证操作的原子性.
每个线程首先尝试给resource赋值, 命令中NX表示只有当resource不存在时才赋值, PX 30000表示设置过期时间为30秒
SET resource my_unique_id NX PX 30000随后线程请求resource的值, 如果与自己的ID相同, 则表示获得锁, 该机制支持同一线程多次获取锁, 实现了可重入性. 线程随后进入临界区执行任务, 完成后通过DEL resource删除该键值对. 如果值与自己的ID不同, 则说明锁被其他线程持有, 线程可选择等待或返回.
此机制不会导致死锁, 因为锁设定了过期时间.
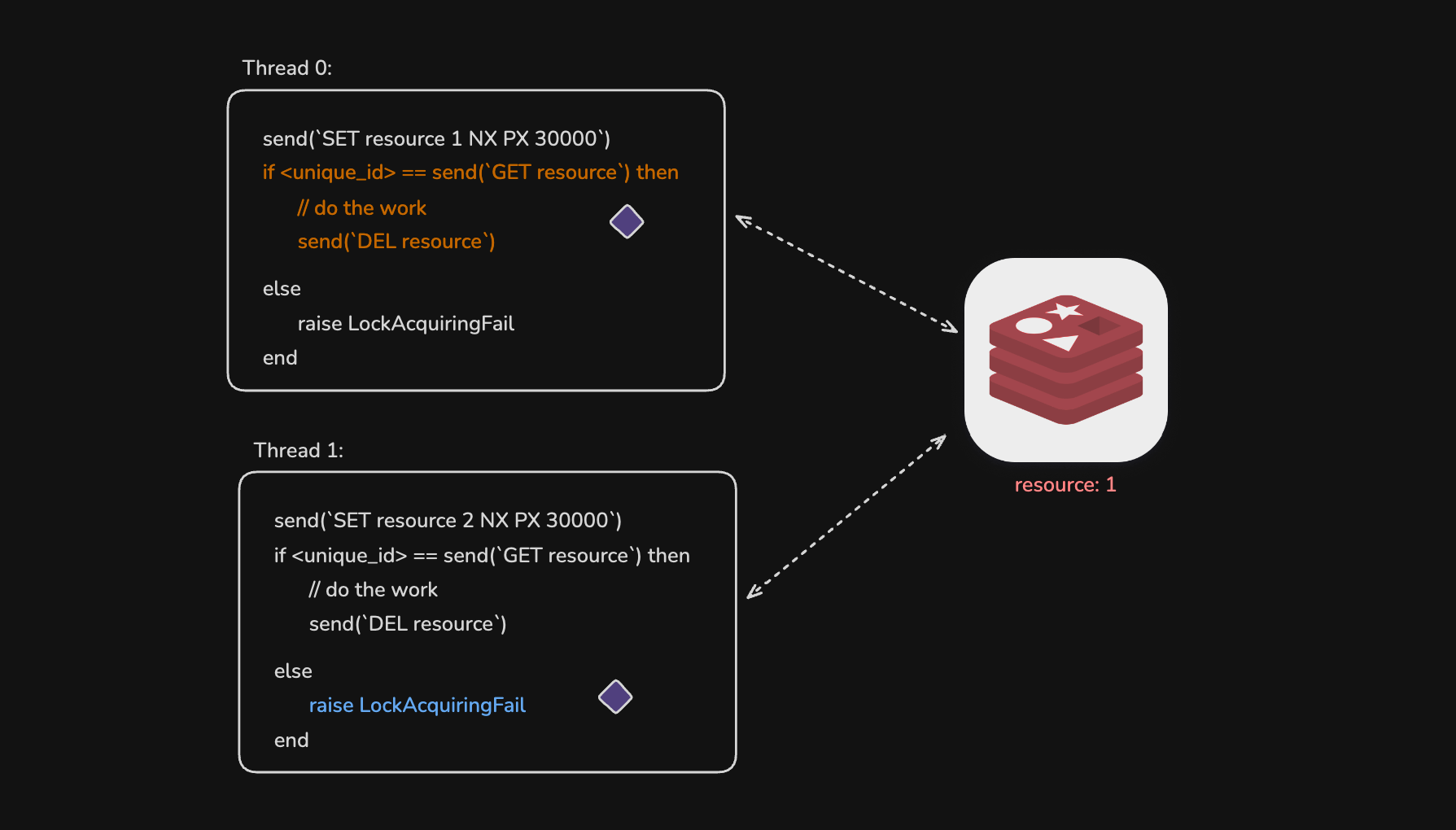
实际工程中的分布式锁实现更为复杂, 此处不再详述.
策略2: 发生错误时补救, Lock-free Solution¶
防止竞争读写导致的错误, 还有一个策略是发生错误时进行补救.
这里我们需要借助处理器指令集提供的原子操作, 在检测到并发冲突时重新计算, 直到确认无冲突后, 才通过原子操作将数据写入.
这些原语有三种, 任意一种都可以实现互斥量和锁, 它们分别是:
- test-and-set
- compare-and-swap
- fetch-and-add
其中比较有名和常用的是compare-and-swap, 也会被简写成CAS. 所谓“乐观锁”或者“lock-free”的算法, 都是使用了CAS函数去实现的.

这个函数的执行是原子化的, 当参数1 == 参数2, 交换参数2和参数3, 否则就什么也不做, 并最终返回参数3.
不同语言中定义略有不同, 参考
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38struct Node { Node* next; int value; }; struct State { Node* top; }; void init(Stack* s) { s->top = NULL; } void push(Stack* s, Node* n) { while (true) { // 找到一种方式来确定没有其他线程修改过数据, 这里是判定old_top是否有改变 Node* old_top = s->top; n->next = old_top; // 如果在compare_and_swap时, s->top == old_top, 说明没有其他的线程在修改s->top // 那么compare_and_swap成功执行, s->top被设定为n, 原来的old_top被返回 // 最终函数将return if (compare_and_swap(&s->top, old_top, n) == old_top) return; } } Node* pop(Stack* s) { while (true) { Node* old_top = s->top; if (old_top == NULL) return NULL; Node* new_top = old_top->next; if (compare_and_swap(&s->top, old_top, new_top) == old_top) return; } }
通过CAS函数可以实现各种乐观锁的算法和atomic类. 所有的pattern都像下面这样: 只要value在整个计算过程中没有发生改变, 结果就能正确覆盖到value上. 否则就重试一次.
1 2 3 4 5while true: origin_value = value new_value = calculate(origin_value) if compare_and_swap(value, origin_value, result): break
线程协同工作¶
Condition variable是用来协同两个互相配合的线程, 让线程可以被挂起或恢复运行. 通过condition variable我们也可以在共享内存模型中(艰难的🥲)实现流水线.
Condition Variable为何臭名昭著¶
condition variable臭名昭著, 这个概念难以理解.
首先, 其命名极具迷惑性: 为什么一个“变量”可以控制线程的挂起和恢复? condition的意思是否与某种判断有关?
实际上, condition variable并非一个变量, 而是一个线程队列.
- 在其上调用await方法, 会让本线程休眠并加入到这个线程队列中.
- 在其上调用
notify/notifyAll(或signal/signalAll)方法, 会弹出并唤醒队列中的线程.
此外, condition variable的使用存在诸多隐含条件: 使用condition variable必须配合锁(lock)一起使用;而condition variable的挂起和恢复操作也会隐式释放和重新获取锁.
如何使用Condition Variable¶
下面通过一个例子说明condition variable的概念和使用细则.
原则上, 使用condition variable的场景是在多个线程基于同一组共享变量是否满足某种条件来决定自身是挂起还是继续运行.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44import java.util.concurrent.locks.Condition; import java.util.concurrent.locks.Lock; import java.util.concurrent.locks.ReentrantLock; class BoundedBuffer { final Lock lock = new ReentrantLock(); final Condition notFull = lock.newCondition(); final Condition notEmpty = lock.newCondition(); final Object[] items = new Object[10]; int putptr, takeptr, count; public void put(Object x) throws InterruptedException { lock.lock(); try { // 根据count决定本线程是否应该挂起(await) while (count == items.length) notFull.await(); items[putptr] = x; if (++putptr == items.length) putptr = 0; ++count; // 唤醒一些线程, 让其继续工作 notEmpty.signal(); } finally { lock.unlock(); } } public Object take() throws InterruptedException { lock.lock(); try { // 根据count决定本线程是否应该挂起(await) while (count == 0) notEmpty.await(); Object x = items[takeptr]; if (++takeptr == items.length) takeptr = 0; --count; // 唤醒一些线程, 让其继续工作 notFull.signal(); return x; } finally { lock.unlock(); } } }
condition variable必须关联一个具体的锁, 因为它需要隐式操作锁.
因此, 声明condition variable时, 要么传入一个锁, 要么通过锁的方法创建. 该锁用来保护共享数据, 确保每次只有一个线程访问共享数据.
condition variable有两组方法: await和notify(或signal). await用于挂起当前线程, notify用于唤醒其他线程. 无论await还是notify, 都必须在持有锁的情况下调用.
当调用signal方法时, 执行以下两步:
- 从队列中弹出一个线程并唤醒它;若调用signalAll, 则唤醒所有线程. 这里的唤醒是将线程状态置为runnable.
被唤醒的线程尝试重新获取锁, 获得锁后从await之后的语句继续执行, 否则继续等待锁的释放.- 需要注意的是, 当线程重新运行时, 条件可能已不再满足. 若条件不满足, 线程需再次调用await加入队列. 因此通常使用while循环来反复检测条件. 线程可能经历多次唤醒和挂起, 直到条件满足.
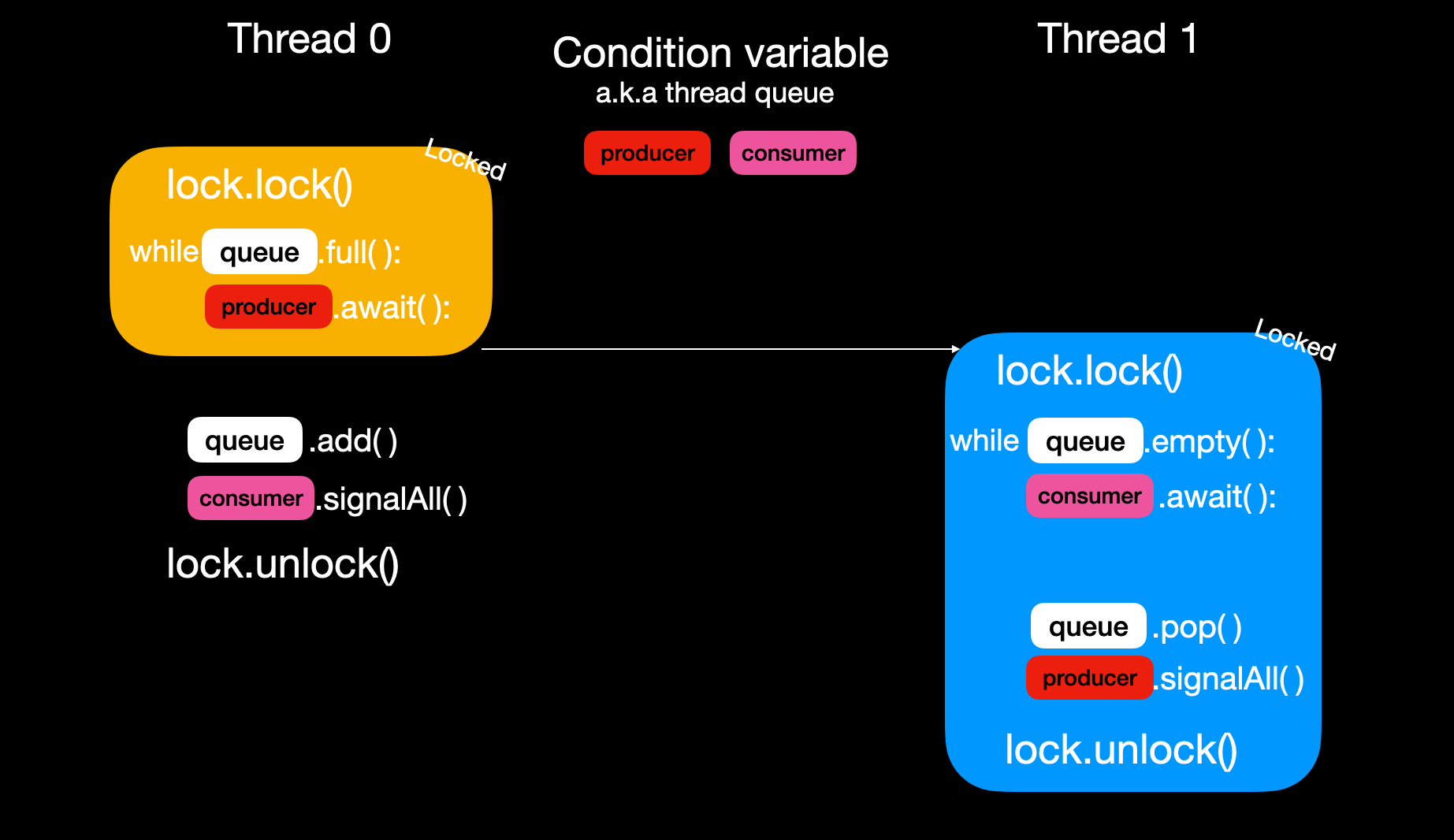
当调用await方法时, 执行以下三步:
- 将当前线程加入队列
释放锁- 挂起当前线程
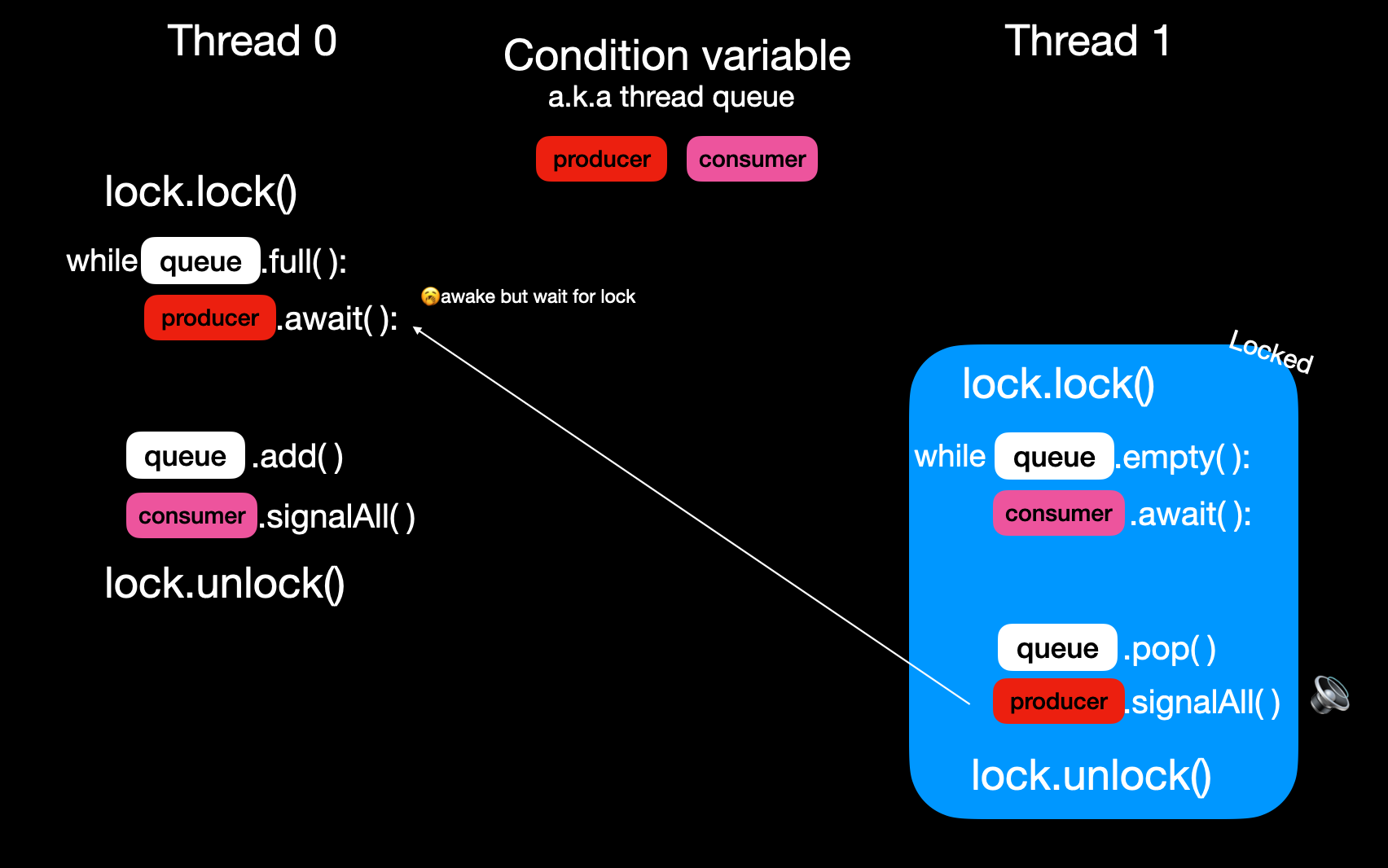
调用signalAll后从队列弹出所有线程并唤醒它们, 这里的唤醒是将线程状态置为runnable, 被唤醒的线程尝试获取锁, 但此时锁还未被释放
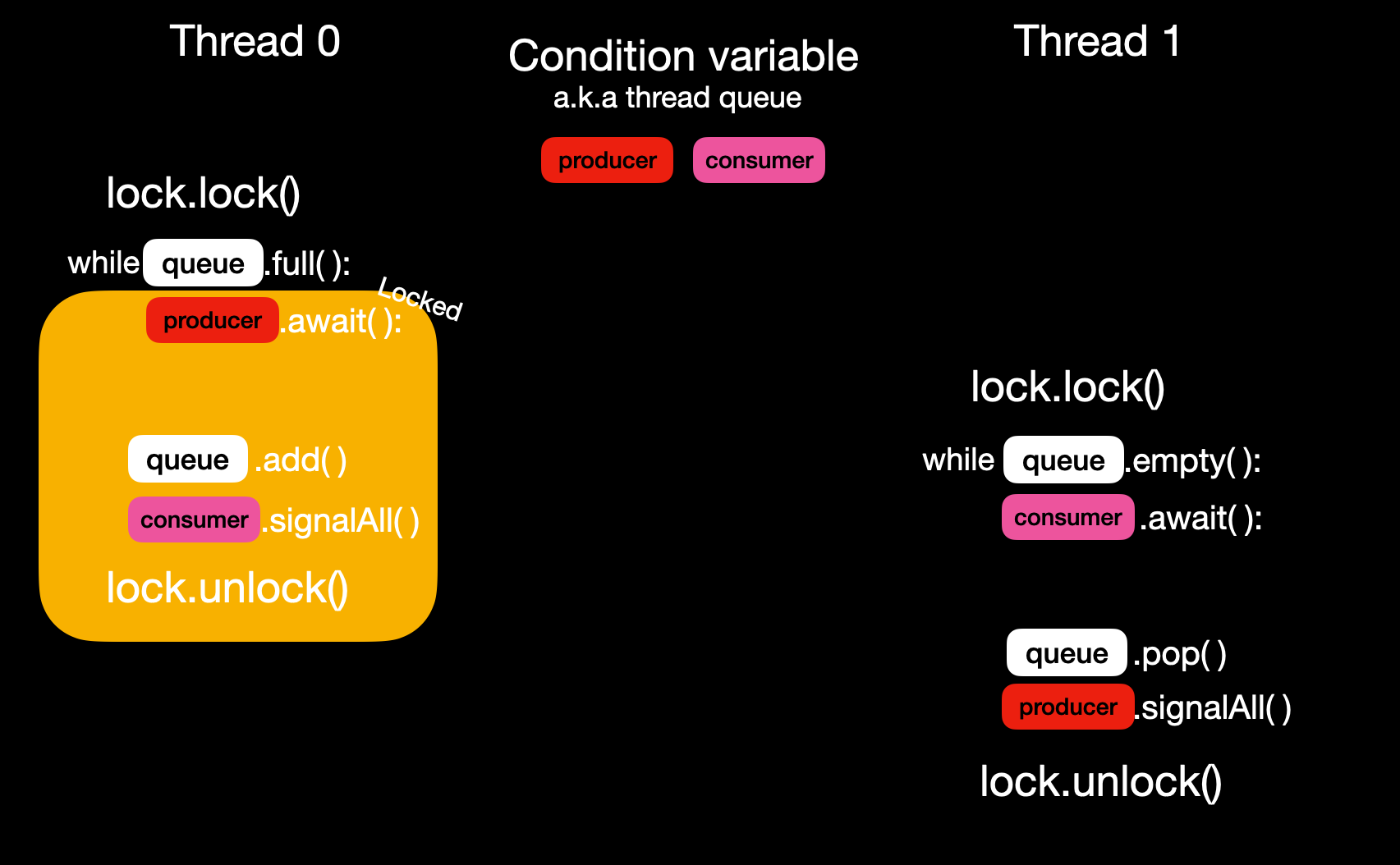
当其他线程释放锁后, 当前线程有可能拿到锁并开始运行await之后的语句. 此时条件可能不在满足, 所以需要再次判断. 所以while的实现不可或缺.
想深入了解其机制, 强烈推荐[1]的第30章.
Condition variable可用于实现一些高级线程同步工具, 例如:
- wait-group(Java中称为countdown latch), 用于挂起主线程, 直到一组工作线程完成后才继续执行主线程.
- cyclic barrier, 使一组线程相互等待, 最终同时完成任务.
可参考Alex Miller的PPT Java Concurrency Idiom.
什么时候用共享内存模型¶
说了这么多, 我们什么时候使用stateful concurrency(共享内存模型)? 它与之前提到的CSP模型有什么区别?
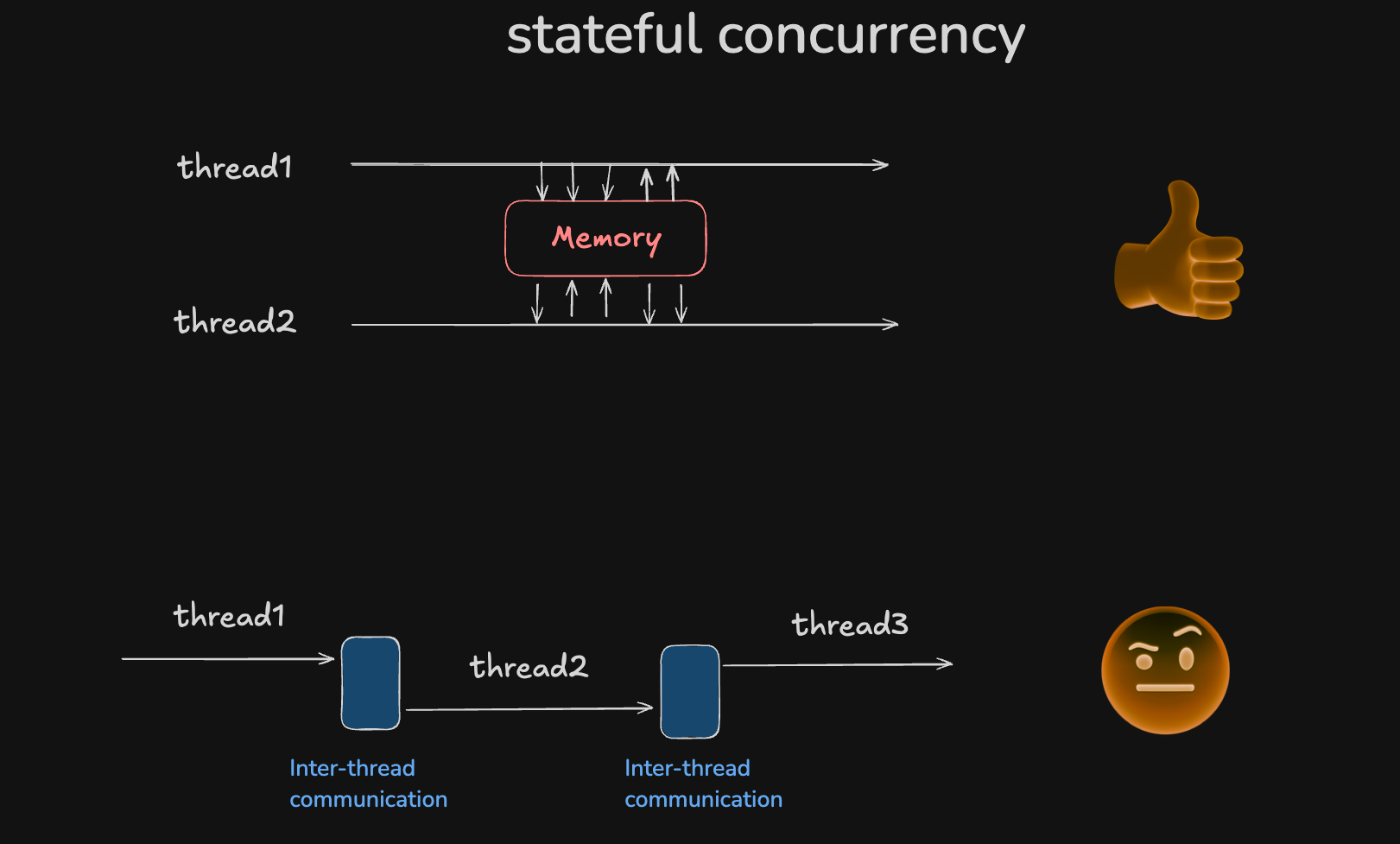
CSP模型适用于实现不同种类线程之间的协同工作场景, 而共享内存模型的优势在于实现同种线程间的竞争工作, 主要目的是加速而非协同. 虽然condition variable也能实现线程协同, 但相比CSP模型, 使用起来更为繁琐.
怎么用好共享内存模型¶
如何更好地使用共享内存模型? 这里分享一点拙见:
业务初期不要盲目使用多线程, 待有需求时再引入多线程加速尽量避免将线程操作混入业务逻辑中, 二者关注点不同, 应保持分离.- 优先使用高级 API, 如线程池, wait-group, cyclic barrier 等, 除非万不得已.
- 优化锁性能时, 应尽可能减小锁的粒度, 并针对读多写少的场景进行优化, 如采用读写锁或无锁(lock-free)方案.