面向并发编程的优点¶
在消息传递模型之后, 我们继续向前, 进入面向并发编程的世界里. 面向并发编程不同于顺序执行的编程范式, 它天然可以用来模拟并发的世界模型, 并且还拥有诸多强大的性质, 包括
- 可扩展性, 只需要增加线程数量, 就能达到扩展系统的目的.
- 较高性能, 能够充分利用系统资源
- 高响应, 因为有海量线程, 因此每个请求到达几乎总有空闲的线程可以立即处理.
- 健壮性, 一个线程崩溃, 并不会影响整个系统
这是面向并发编程的优点.
面向并发编程的范式¶
面向并发编程不同于顺序执行的编程范式.
如果你有过后端开发经验, 可以回想一下, 一个service能够做什么. 无论采用何种协议, service总会提供一组API, 其他进程可以向其发送请求并获得相应的响应. service可以用来执行某种计算任务, 类似于运行在其他进程中的函数;一旦service具备存储能力, 我们还可以对其进行读写操作, 类似于声明在其他进程中的数据容器.
面向并发编程即在一个系统进程中启动若干线程, 这些线程既可以作为计算单元, 也可以作为数据容器. 线程之间能够相互通信. 其他线程可以发送消息, 调用这些服务线程所提供的功能, 也可以接收服务线程发送的消息以获取返回值.
Elixir代码示例如下.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53defmodule Calculator do # 服务入口 defp loop(current_value) do new_value = receive do {:value, caller} -> send(caller, {:response, current_value}) current_value {:add, value} -> current_value + value {:sub, value} -> current_value - value {:mul, value} -> current_value * value {:div, value} -> current_value / value invalid_request -> IO.puts("invalid request #{inspect(invalid_request)}") current_value end loop(new_value) # 通过尾递归实现无限循环 end def start do spawn(fn -> loop(0) end) end def value(server_pid) do send(server_pid, {:value, self()}) receive do {:response, value} -> IO.puts("the result is #{value}") end end def add(server_pid, value), do: send(server_pid, {:add, value}) def sub(server_pid, value), do: send(server_pid, {:sub, value}) def mul(server_pid, value), do: send(server_pid, {:mul, value}) def div(server_pid, value), do: send(server_pid, {:div, value}) end pid = Calculator.start() # 创建一个线程, 其中有一个计算服务 Calculator.add(pid, 5) # 对服务发送add消息 Calculator.mul(pid, 10) # 对服务发送mul消息 Calculator.value(pid) # 对服务发送value消息, 并打印返回值
该例子来自[1]
在顺序执行模型中, 我们创建一个数据容器去管理数据或调用函数进行某种计算或执行某种任务, 在面向并发编程中, 我们启动一个service线程, 并利用它去管理数据或者进行计算. 线程之间通过消息的发送和接收进行通信.
什么时候使用面向并发编程¶
但如果我就写个a + b, 有必要启动一个求加法的service吗?
面向并发编程并不意味着你要用service解决一切问题. 至于选择本地调用还是服务 + 消息, 全看需求.
什么时候选择service, 而不是本地函数调用呢?
- 如果
需要管理一下长期存在的状态, 譬如我想要管理从系统启动以来的qps的数据, 选择service. - 如果
需要管理一些需要被复用的资源, 譬如数据库连接, TCP连接, 或者文件句柄等等, 选择service. - 如果
有一段代码使用到了某些资源, 需要被互斥的运行, 我们可以把这段代码放到service线程中, 如此一来就规避了竞争读写的问题. - 需要
承接大量IO请求的时候, 也可以选择service, 通过启动大量用完即弃的线程来承接大量IO请求.
以上就是在面向并发编程的范式下, 选择service而不是本地函数调用的场景.
上述面向并发编程可能会让你联想到微服务, 二者在某些方面确实有相似之处. 面向并发编程属于语言范畴的概念, 而微服务则属于应用架构范畴. 尽管两者处于不同领域, 但存在许多高度相似的实践. 理解面向并发编程, 有助于更好地理解微服务的实践, 甚至能在其中发现云原生应用中的对应概念.
Actor Model¶
虽然我们可以开启大量线程协同工作, 但在至少在CSP模型中, 代码仍显得冗长繁复.
原因在于, CSP模型抽象了线程间数据交换, 使这部分代码简化, 但线程的启动, 管理以及指定数据流向仍需手动操作, 大部分冗长代码正是用于完成这些工作.
最早由Carl Hewitt提出的Actor模型, 旨在进一步抽象线程管理和数据流向, 使得语言更适合面向并发编程. Actor模型并非与某种语言强绑定, 许多语言均有各自的Actor模型实现.
Carl Hewitt
计算机科学家, 提出Planner编程语言和Actor模型
Joe Armstrong

Erlang的三位作者之一, Erlang将actor model发扬光大
Actor model和CSP Model的不同之处¶
Channel vs Message¶
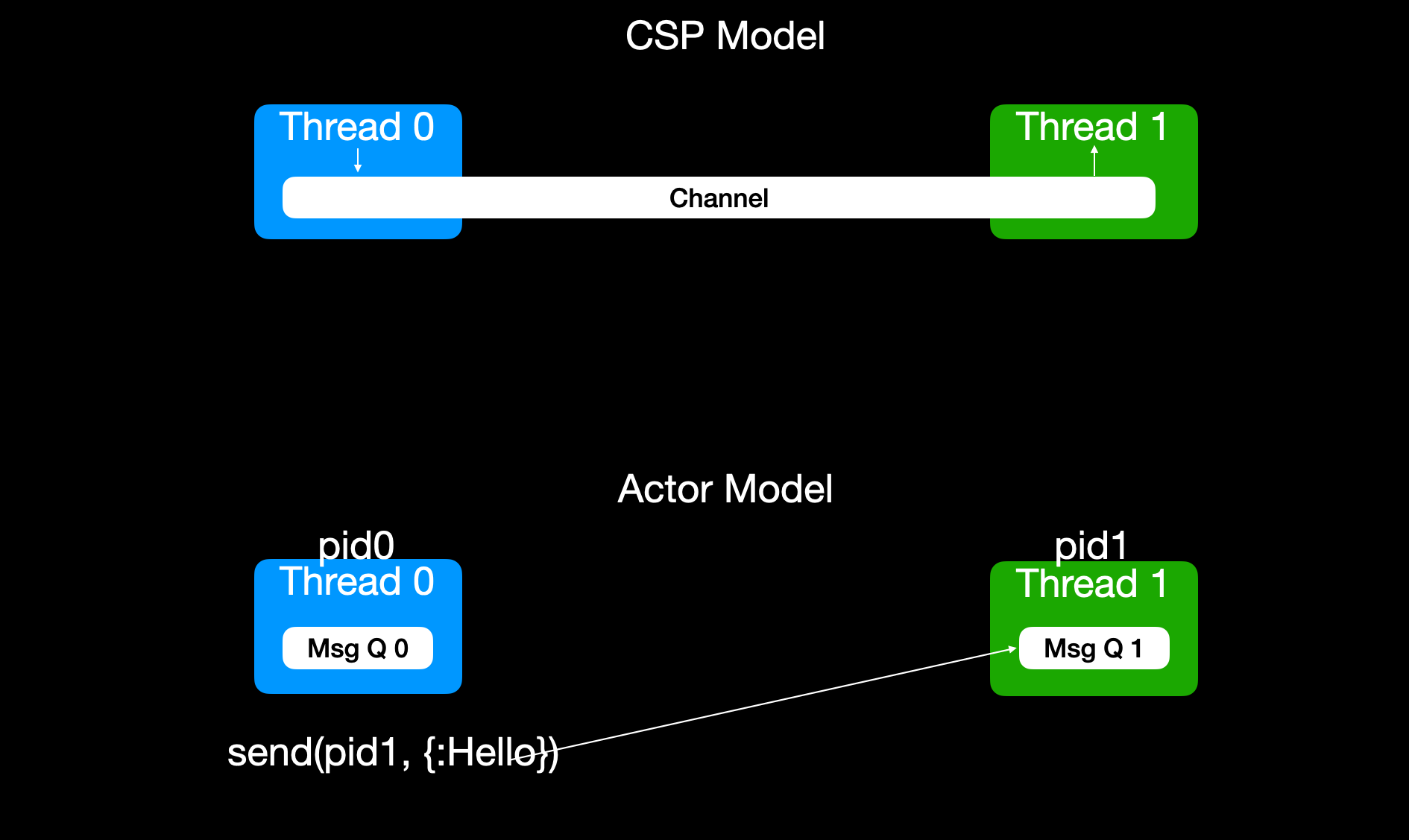
在actor model中, 我们不再像在CSP model中显式创建channel, 取而代之的是每个线程启动后都会创建自己的专有队列, 专门接收发往本线程的消息.
每个线程创建之后会返回一个线程id, 但在面向并发编程的传统里, 我们称为process id, 简称pid. 其他线程只需要向这个pid发送消息即可.
我们不再需要像CSP model中一样, 手动传递channel, 然后通过channel来收发数据, 而是通过send(pid, {:name, field1, field2, ...})语句发送消息.
在线程中收信息时, 我们也不用select + channel, 而是使用receive关键词, 直接从专有队列中抽取消息, 进行模式匹配. 匹配上的消息则进行相应处理.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20defmodule Talker do def loop do receive do # we do use receive to handle incoming message {:greet, name} -> IO.puts("Hello ${name}") {:praise, name} -> IO.puts("#{name}, you're amazing") {:celebrate, name, age} -> IO.puts("Here's to another #{age} years, #{name}") {:shutdown} -> exit(:normal) end loop end end Process.flag(:trap_exit, true) pid = spawn_link(&Talker.loop/0) send(pid, {:greet, "John"}) send(pid, {:praise, "Wade"}) send(pid, {:celebrate, "Louis", 18}) send(pid, {:shutdown})
孵化Talker线程后, 我们会获得该线程的pid, 通过向pid发送消息来触发Talker中对应的处理函数. Talker调用loop方法并递归执行, 相当于循环运行该方法. receive在消息队列为空时会挂起线程, 待有消息时恢复运行, 类似于CSP模型中的select. 该例子来自[1]
Heart beat vs link¶
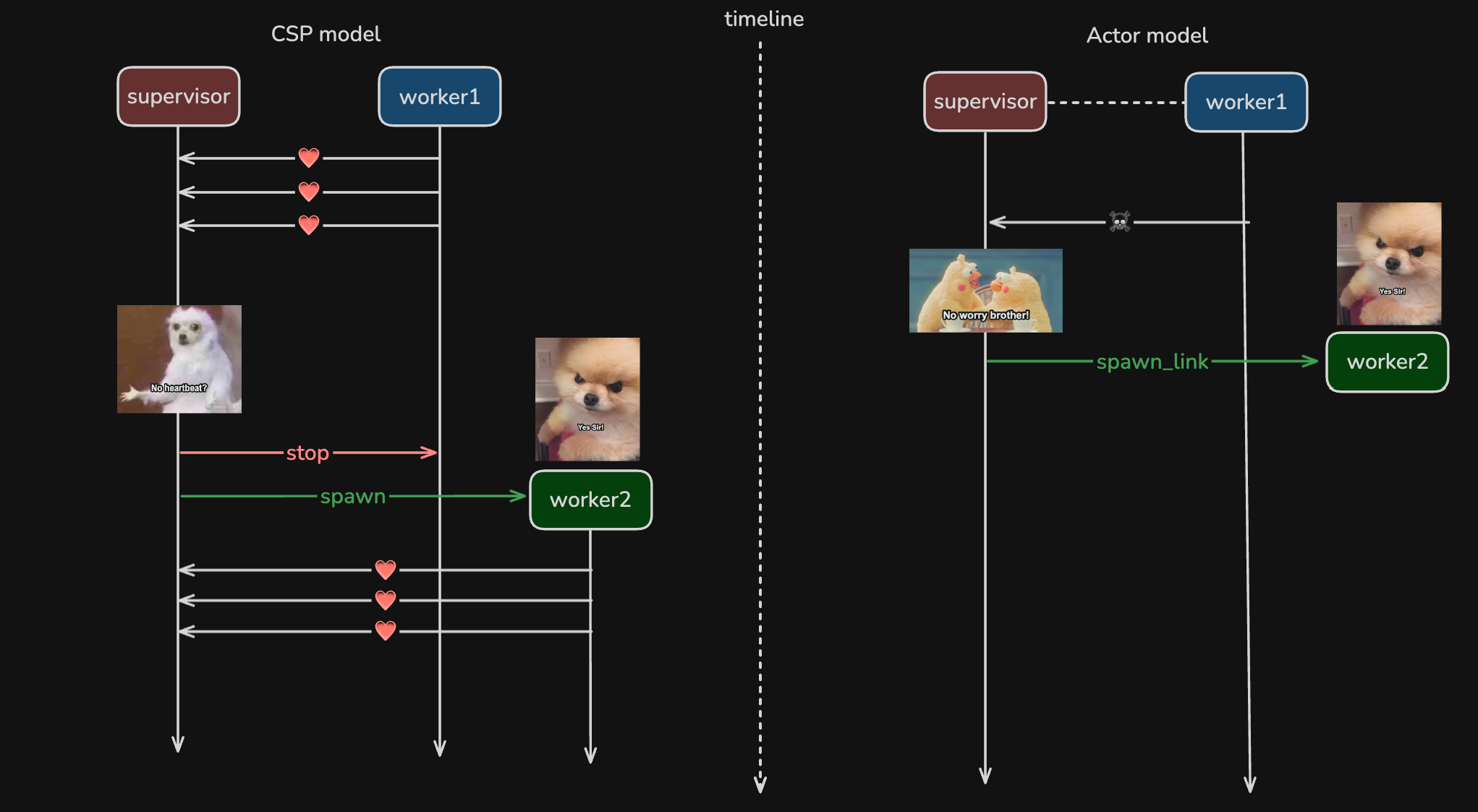
Actor model中两个线程可以link在一起, 其中一个崩溃退出, 另一个也会受到exit消息. 如果我们trap exit消息, 就可以在收到exit消息时进行重启操作.
Actor model中线程可以link在一起, 其中一个崩溃退出, 另一个也会收到exit消息, 这种机制让线程之间的管理变得方便, 因为我们不再需要手动构造心跳机制了. 下面例子中, 我们通过spawn_link创造一个跟当前线程link在一起的线程. 我们也可以使用OTP库中的GenServer和Supervisor module来创建link在一起的线程.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21defmodule Example do def start do # 设置收到exit信号之后, 不会自行退出 Process.flag(:trap_exit, true) # 孵化一个线程并链接, 这个线程1s之后就退出 pid = spawn_link(fn -> # Simulate some work then exit :timer.sleep(1000) exit(:normal) end) # 接收并处理exit消息 receive do {:EXIT, ^pid, reason} -> IO.puts("Linked process exited with reason: #{inspect(reason)}") end end end Example.start()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52defmodule Worker do use GenServer # 客户端API def start_link(_) do # 启动GenServer进程并链接当前进程 # __MODULE__表示当前模块Worker # :ok是传递给init回调的初始状态参数 # []表示启动选项, 这里为空 # 返回值 {:ok, pid} 表示启动成功, pid是进程ID GenServer.start_link(__MODULE__, :ok, []) end # 服务器回调 def init(:ok) do # 设置当前进程为trap_exit模式, 允许接收退出信号消息 Process.flag(:trap_exit, true) {:ok, %{}} end def handle_info(:do_work, state) do # 模拟工作后正常退出进程 exit(:normal) {:noreply, state} end end defmodule SupervisorExample do use Supervisor def start_link(_) do # 启动Supervisor进程并链接当前进程 # __MODULE__表示当前模块SupervisorExample # :ok是传递给init回调的参数 # name: __MODULE__ 给Supervisor注册一个全局名称, 方便查找 Supervisor.start_link(__MODULE__, :ok, name: __MODULE__) end def init(:ok) do children = [ {Worker, []} # 启动Worker模块作为子进程, 传递空参数 ] # 采用one_for_one策略: 如果子进程退出, 只重启该子进程 Supervisor.init(children, strategy: :one_for_one) end end # 运行示例: # 当前线程孵化Supervisor线程, Supervisor线程孵化Worker线程 # 这里使用了GenServer宏去规范Worker的API, 使用Supervisor宏去快速实现一个supervisor {:ok, sup} = SupervisorExample.start
Actor模型提出了一种非常强大的范式, 能够极大地影响代码的组织结构. 相比底层的CSP模型和共享内存模型, Actor模型更为高级, 但代价是通用性较低. 因此, 与其他更通用的范式相比, 它主要用于并发问题的建模.
Actor Model中的特定写法¶
如何拿到返回值¶
Actor模型整体倡导“fire and forget”的风格. 我们启动一个线程去完成特定任务, 但线程一旦创建便不再管理, 也不期待返回值;或者对于一个已存在的服务线程发送消息, 消息一旦发送便不再管理, 也无法获得对方处理消息后的响应. 那么, 当我们需要任务的返回值时该如何处理? 能否像调用函数那样, 调用完毕即可获得返回值?
此时需要实现一种同步机制, 采用spawn+receive或send+receive的方式. 先启动任务或发送消息, 在任务参数或消息体中携带自身线程的pid, 然后立即调用receive, 等待接收对方发送的响应消息. 这种写法是Actor模型的典型特征, 具体示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29defmodule main do def call(pid, msg) do # 发送消息时, 在消息体中带上当前线程的pid, self()返回当前线程的pid send(pid, {self(), msg}) # 在发送消息之后立即监听可能的response消息, response的格式需要提前协定 receive do {:response, resp} -> IO.puts("response is #{resp}") end end def loop() do receive do {caller_pid, msg} -> ultimate_msg = 42 # 从收到的消息中提取caller的pid, 在计算完毕后对caller发送response消息 send(caller_pid, {:response, ultimate_msg}) other_msg -> IO.puts("received unknown message: #{inspect(other_msg)}") end loop() end end
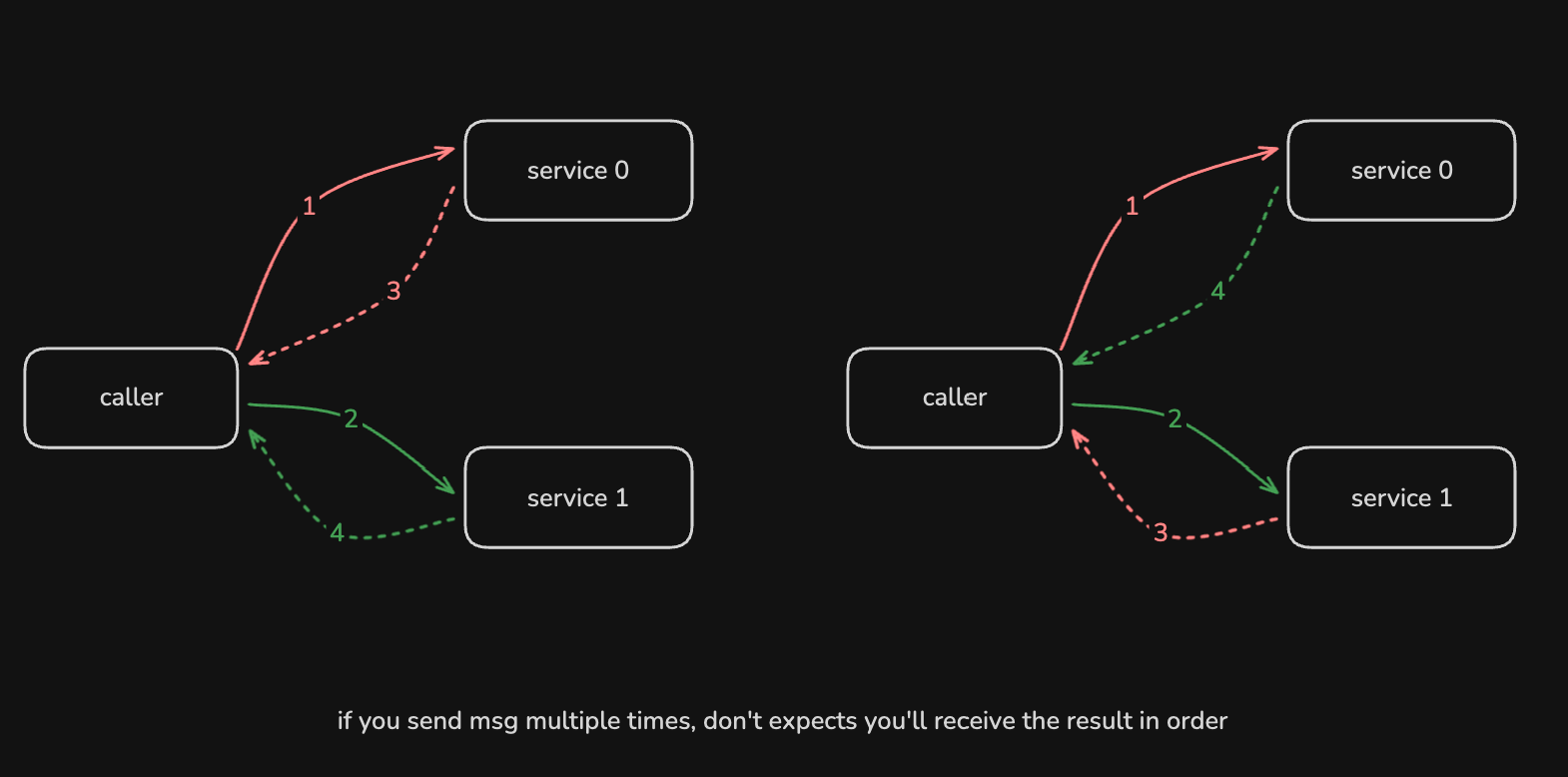
这种写法带来一个问题: 如果一次性发送多个请求, 响应消息未必按顺序到达, 从而引发一定限制.
如何"跳出"复杂的递归函数¶
出于某种原因, 原生支持actor model的语言, 譬如erlang或elixir, 其底层都是declarative model, 因此这两门语言中都没有循环, 都需要使用递归, 一些复杂的递归会层层嵌套. 如果我需要从嵌套很深的地方退出递归怎么做呢? 我们可以使用throw, 抛出一个“异常”, 然后外层catch住, 以此来退出嵌套递归.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20defmodule RecursionThrow do def nested_recursion(n) when n <= 0 do throw({:stop, "Reached base case"}) end def nested_recursion(n) do IO.puts("Processing #{n}") nested_recursion(n - 1) end def run do try do nested_recursion(5) catch {:stop, message} -> IO.puts("Stopped recursion: #{message}") end end end RecursionThrow.run()
什么时候使用actor Model¶
使用actor model的前提是需求本质上涉及并发问题, 即多个主体需同时运行并实时交互.
如果需求是同质线程对有限资源的竞争利用, actor model则不太适合, 它不适用于大规模的数据批处理(batch data processing). Actor model更强调不同主体的独立运行, 通过异步消息进行沟通, 从而编织计算逻辑. 它侧重于大规模异步业务逻辑的执行, 而非大规模同步数据处理.
因此, actor model适用的主要场景包括:
- 服务器端系统, 最经典的例子是 Web 服务器
- 分布式系统, 尤其是任务具有强时效性的分布式系统, 例如电梯调度模拟, 电子电路系统模拟等.
怎么使用Actor Model?¶
所以使用actor model有什么特定的pattern或者特定的应用呢?
Stateful Service中的pattern: 有限状态机¶
简单的service可以是无状态的. 而复杂的service可以拥有状态. 每个有状态的service都是一个有限状态机. 根据自身当前的状态, 以及收到的消息, 来判定当下应该执行什么逻辑, 以及更新到什么状态. 代码以这种形式展现是因为语言中没有循环, 所以要以尾递归的方式实现循环. 而状态作为每一次递归的参数存在. 这种写法非常普遍
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16def start do spawn(fn -> initial_state = ... loop(initial_state) end) end defp loop(state) do next_state = receive do msg1 -> ... msg2 -> ... end loop(next_state) end
Supervisor Tree¶
回顾上面CSP model中, 会有一些线程是supervisor. 在actor model中, 也有类似的管理线程, 当worker线程出错退出时, supervisor线程会收到消息, 并负责重启worker线程. Actor model提供了link机制, 使两个线程连接在一起, 一个崩溃退出, 另一个也会收到相应的exit信号.
我们可以利用该机制, 将所有worker线程与supervisor线程连接起来. 一个Supervisor管理一组Worker. 而当Supervisor本身出错停止时, 它也需要被重启, 所以Supervisor应该由更高层的Supervisor负责管理.
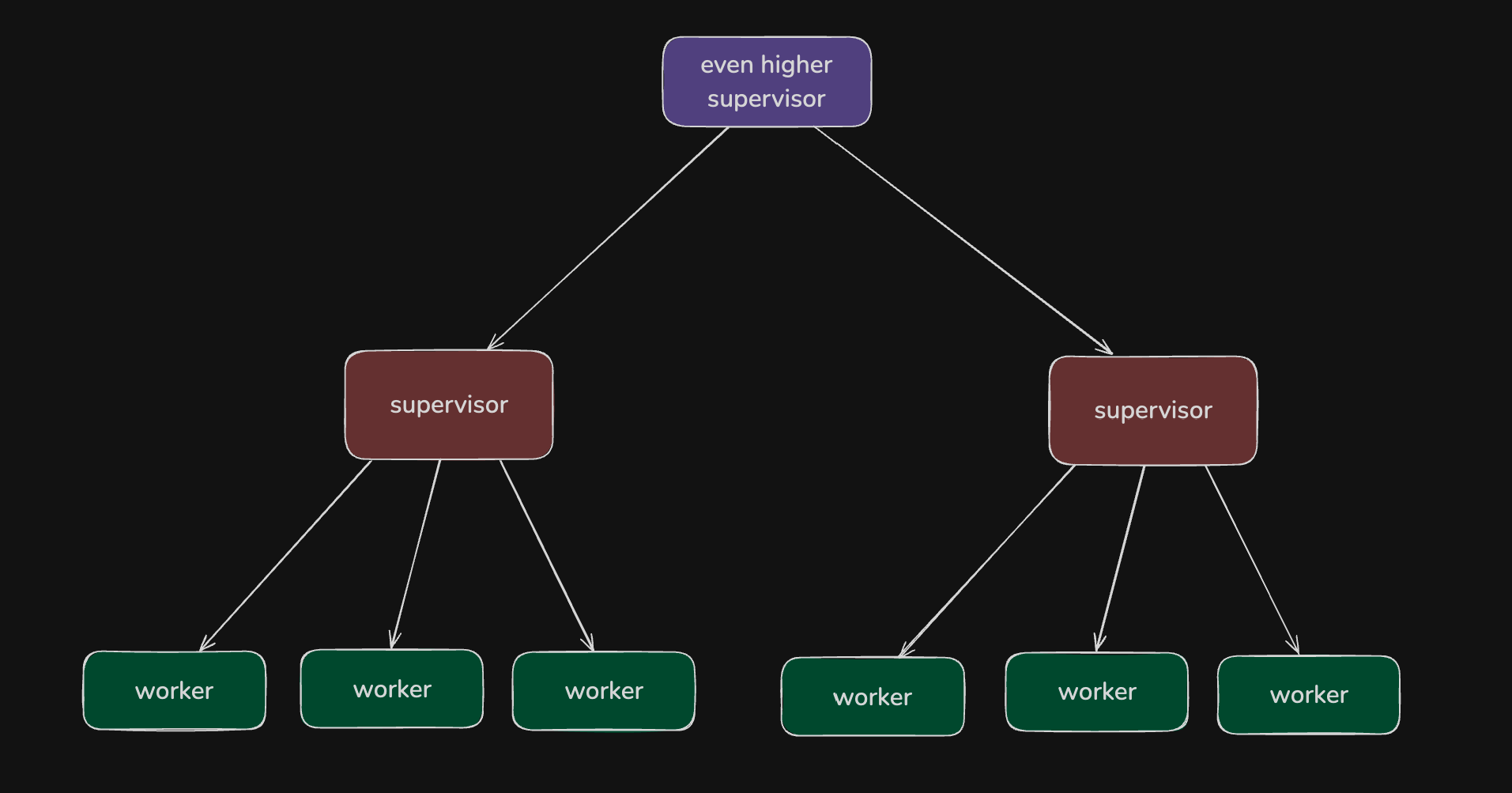
一组线程被一个supervisor线程管理, 如此层层递进, 形成了supervisor tree.
由于该模式极为常用, Erlang和Elixir的OTP库中提供了GenServer和Supervisor宏, 方便快速实现supervisor tree. 参考Program 3
Name Service¶
另一种应用模式是名称服务(name service).
在actor model中, 使用pid作为线程的地址进行消息收发, 但pid本身不易记忆, 且线程关闭重启后, pid会发生变化. 为pid起一个稳定的别名, 可以简化线程间的交互.
如果存在一种机制, 能够将别名映射到pid, 那么我们只需记住别名, 使用时查询对应pid即可.
在actor model中, 通常将提供名称到pid映射的功能实现为一个服务, 供其他线程使用, 我们称之为Name service.
这一概念在网络服务中对应DNS服务器, 在分布式系统中对应Zookeeper或Kubernetes中的Service, 是分布式系统中的常见服务.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42defmodule NameService do use GenServer def start_link(_) do # 初始state是一个空的Map GenServer.start_link(__MODULE__, %{}, name: __MODULE__) end @doc "Register a name with a pid" def register(name, pid) when is_pid(pid) do GenServer.call(__MODULE__, {:register, name, pid}) end @doc "Lookup the pid by name" def lookup(name) do GenServer.call(__MODULE__, {:lookup, name}) end @doc "Unregister a name" def unregister(name) do GenServer.call(__MODULE__, {:unregister, name}) end def init(state) do {:ok, state} end # 关注以下handle_call方法 def handle_call({:register, name, pid}, _from, state) do {:reply, :ok, Map.put(state, name, pid)} end def handle_call({:lookup, name}, _from, state) do {:reply, Map.get(state, name, :undefined), state} end def handle_call({:unregister, name}, _from, state) do {:reply, :ok, Map.delete(state, name)} end end
Key-value Storage¶
还有一种分布式系统中常用的服务是键值存储服务, 类似于 Redis, etcd 等. 它方便不同线程之间共享数据, 或用于记录集群自身的状态与配置.
此处不再提供代码示例, 有兴趣可参考[1]一书.
以上就是面向并发编程和actor model的全部内容.
Elixir in Action, 作者Saša Jurić, 2015年出版