协程历史¶
在CPU仍为单核的时代, 并发这一概念其实已经存在. 那时的并发主要是为了让计算机在同一时间段内能够响应多个任务. 为了实现这一点, 计算机必须不断切换当前执行的上下文.
当时存在两种设计思路:
- 由硬件和操作系统负责上下文切换, 对应用程序而言是透明的, 每个应用程序都认为自己独占了机器. 这催生了进程和线程等概念
- 应用程序自身负责上下文切换, 每个线程在运行一段时间后主动挂起自己, 允许其他线程执行, 具体操作由程序员控制
虽然第二种设计最终未广泛流行, 但线程主动挂起的能力被证明非常有用. 于是操作系统提供了 yield 函数(此处称为 thread-yield, 以区别后续概念), 调用 thread-yield 使线程主动挂起自己, 交由操作系统调度其他线程执行.
尽管我们可以主动挂起线程, 但线程间的调度仍由操作系统决定. 想要在线程 A 挂起时, 指定线程 B 继续执行是不可行的, 因为下一个执行的线程由操作系统决定, 可能是除 B 以外的任意线程.
为了达到用户控制执行上下文切换的目标, 首先我们要绕过操作系统, 完全在用户态完成这项工作.
也是因为要绕过操作系统, 我们不能把任务分散到多个线程中, 而是集中在一个线程里, 然后提供一些新特性, 让应用程序能够在单线程中主动切换执行上下文.
协程引入的新特性¶
为了在用户态切换上下文, 引入了两个新的关键词
- yield / co_yield
- next / resume / cowait / await
不同的语言中使用了不同的名字, 我们这里取python中的关键词命名进行后续说明, 也就是yield和next. 下面用一个例子来说明它们.
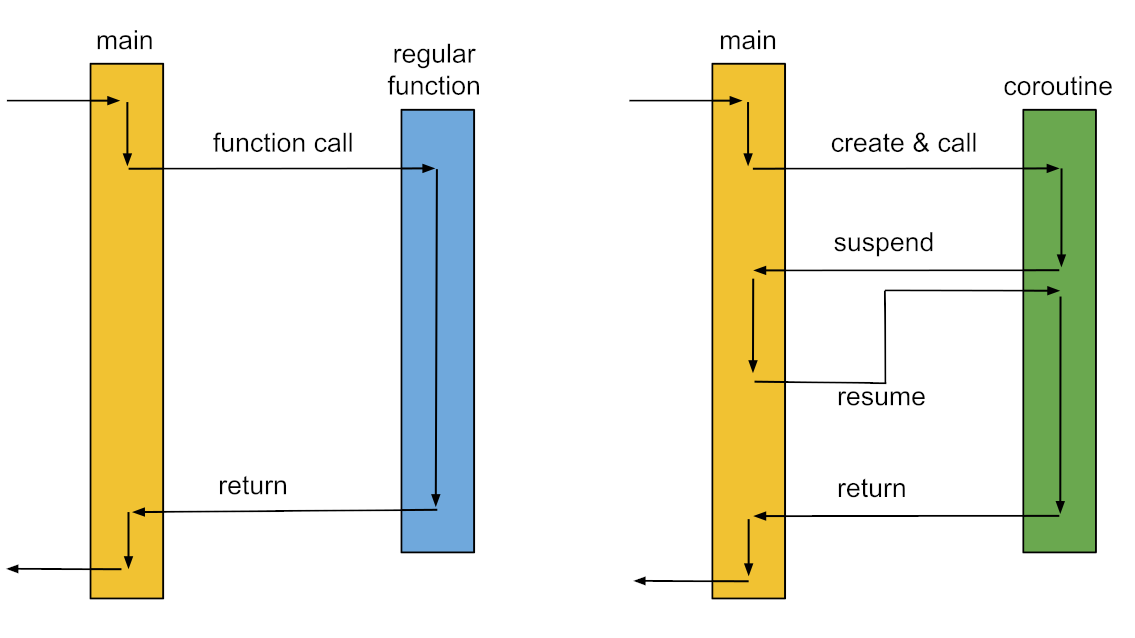

当某个函数function2中使用了yield关键词, 它就不再被当成一个普通函数, 调用它不会直接运行function2, 而是会生成一个特殊对象.
而在这个特殊对象上进行next操作, 执行上下文会切换到function2进行执行, 直到function2使用了yield, 执行上下文则切回调用它的地方.
而此时function2的上下文并没有被回收, 因为它还没有执行完. 在main中再次调用next会再次切回function2, 执行剩下的代码, 以此类推

yield <value>会把<value>传回调用next的协程co.send(<value>)会把<value>传到协程里, 作为yield语句的返回值
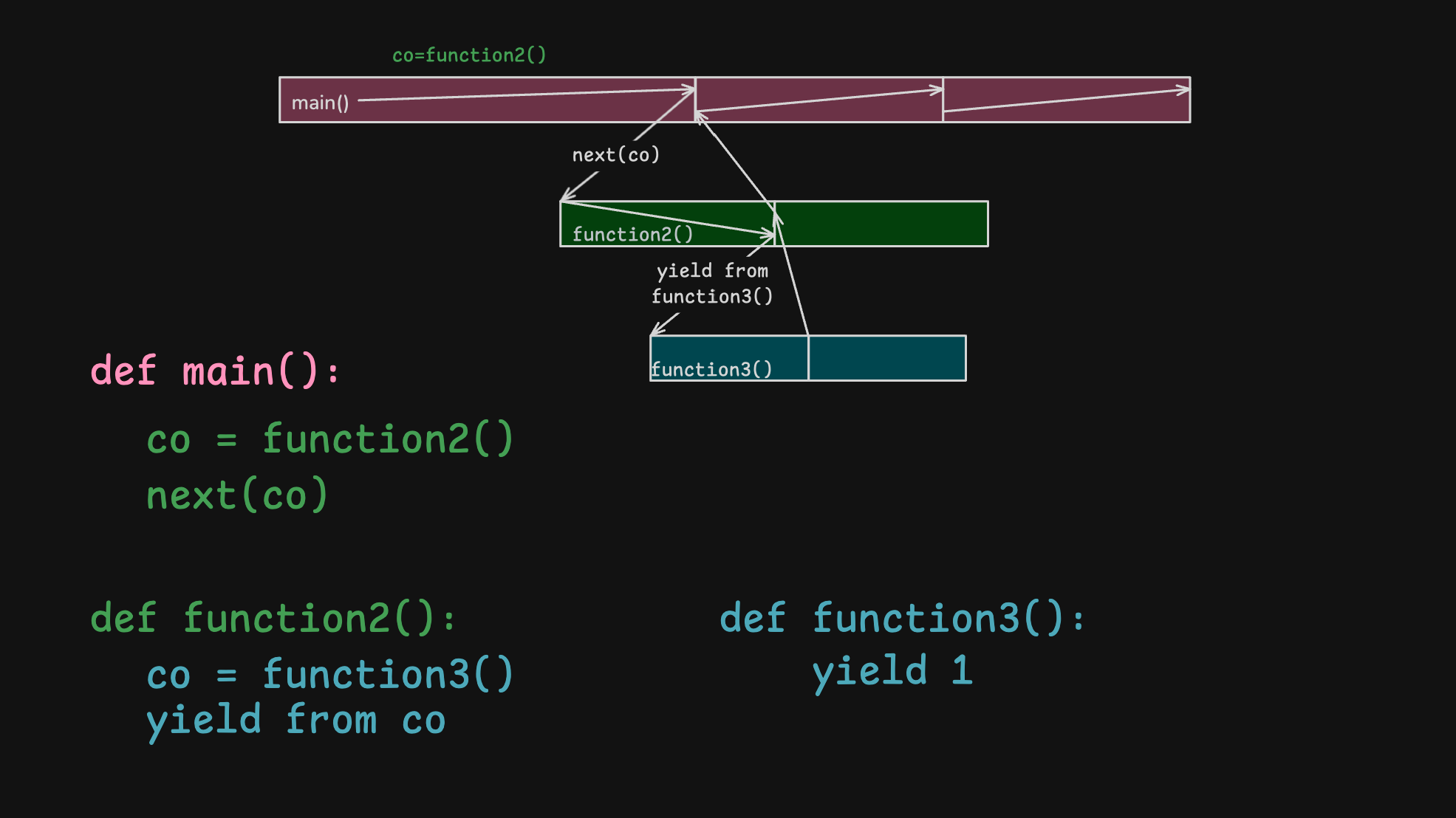
使用yield from <coroutine>就可以在一个coroutine中调用另一个coroutine
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22def sub_coroutine(): print("Sub-coroutine started") value = yield print(f"Sub-coroutine received: {value}") value = yield value + 5 print(f"Sub-coroutine received again: {value}") return "Sub-coroutine done" def main_coroutine(): print("Main coroutine started") # Delegate to sub_coroutine result = yield from sub_coroutine() print(f"Sub-coroutine returned: {result}") value = yield "Main coroutine result" print(f"Main coroutine received: {value}") coro = main_coroutine() next(coro) print(coro.send(10)) # sends 10 to sub_coroutine, yields 15 (10 + 5) print(coro.send(20)) # sends 20 to sub_coroutine, sub_coroutine returns print(coro.send(30)) # sends 30 to main_coroutine
简单的代码示例
刚才我们提到了协程, 这里跟线程对比一下.

线程需要一个函数作为入口. 协程也是如此.
线程可以调用thread-yield去挂起自己. 协程可以通过yield把控制还给caller.
操作系统能够恢复线程的运行. caller能通过next恢复协程的运行.
正因为概念上有很多对应, 所以很多人才为此命名协程, 这是为了跟线程对应起来.
什么时候使用协程¶
什么时候使用协程这一套概念呢?
首先, 协程并不会提升计算效率, 因为所有协程都运行在同一个线程中, 计算能力并未增加. 但协程可以显著提升IO效率, 尤其是在需要等待IO完成的场景中, 可以挂起当前协程, 切换运行其他协程, 从而提高资源利用率.
尽管如此, 在实际工作中, 我们很少自行开发完整的协程库来调度协程提升IO效率, 通常直接使用语言提供的async特性. 相比之下, yield/resume机制更为底层, 完整实现调度机制工作量较大, 不如直接采用更完善的async特性.
在日常工作中, 我们更多使用yield/resume来快速实现业务相关的生成器或状态机.
生成器¶
生成器是一种对象, 提供next方法和一个能感知到生成结束的机制
生成器可以放到循环中, 就像遍历一个Array. 但它的优势是lazy execution, 在你需要值的时候才去算一个出来. 像是无限数列就可以用生成器进行抽象. 使用生成器可以让一些函数式的代码变得更加简单.
1 2 3 4 5 6 7def my_generator(n): for i in range(n): yield i gen = my_generator(5) for value in gen: print(value)
状态机¶
状态机也是一种对象, 它拥有一组状态, 根据它当前的状态和用户输入, 决定它的输出(或副作用)以及下一个状态. 用yield和send可以很方便的实现一个简易的有限状态机.
1 2 3 4 5 6 7 8 9 10 11 12 13 14def traffic_light(): state = "red" yield state while True: input_ = yield state if input_ == "PedestrianWaiting" and state == "green": state = "red" elif input_ == "CarWaiting" and state == "red": state = "green" light = traffic_light() assert light.send("CarWaiting") == "green" assert light.send("PedestrianWaiting") == "red"
总之, 一些能够执行, 同时需要保留状态的对象, 我们都可以尝试使用协程去实现, 只要用协程实现更简便. 除此之外, 一般我们都会尽可能缩小yield / resume的使用范围. 在代码中不加审慎的使用协程会让代码变得难以理解.