Modular model几乎成为工程的标配, 是为数不多被广泛认可的模型.
除了一些较早的语言和极少数现代语言之外, 几乎所有语言都支持模块化编程. 有些语言甚至强制要求按模块组织项目结构.
Modular Model带来的新特性¶
这个模型增加了两个新特性: 模块封装和访问控制.
首先, 它引入了module的概念. module是一个容器, 我们可以将相关的一组常量, 函数, 类型定义(包括 struct 和 enum), 以及后续将提及的类, 放在同一个容器中. 调用时需要在前面指定<module-name>., 表示调用的是该 module 中的内容. 这样一来, 所有常量, 函数, 类型和类等元素都有了归属, 避免了同名函数冲突的问题(当然, 如果 module 名称冲突仍然存在). 此外, 大模块内部还可以继续拆分成若干小模块, 层层拆分形成模块树, 最终叶子模块只承载必要的一小部分元素, 变得简洁精炼.
另一个特性是元素的访问控制. 绝大多数语言都提供相关关键词, 例如标记为可访问(公有)的public / export / pub, 或标记为不可访问(私有)的 private / defp 等等. 有些语言不支持强制的访问控制, 但在实践中通过特殊命名表明该元素是否是"私有的", 如python中以下划线开头的函数名表示私有, 不推荐外部引用.
这两个特性看似简单, 实则作用巨大.
接口定义¶
模块提供了访问控制, 通过隐藏外接无序了解的元素, 来强调真正重要的, 逻辑单元之间交互必须使用的元素, 从而大大简化逻辑单元之间交互的复杂性. 这种实践是迪米特法则的一种实践.
1 2 3// 暴露少量方法 fetch(Api) -> Data toString(Data) -> String
通过module暴露的少量方法能快速了解代码的意图, 这里module用来访问API
1 2 3 4 5 6 7 8// 暴露全部方法 isValid(Api) -> bool host(Api) -> String path(Api) -> String resolveHost(string) -> Ip request(Ip, String) -> Data toString(Data) -> String fetch(Api) -> Data
当所有方法都公有时, 难以快速了解作者意图, 难以快速选出主要方法
代码组织¶
模块提供了一种代码组织规范, 属于同一个模块的元素, 应该聚合在同一个文件或同一个路径下(物理距离接近). 这种组织规范能大大简化代码组织和管理.
leaf_engine/
├── Cargo.toml
├── .gitignore
├── src/
│ ├── main.rs
│ ├── app/
│ │ └── mod.rs
│ ├── asset/
│ │ ├── loader.rs
│ │ ├── texture.rs
│ │ └── model.rs
│ ├── audio/
│ │ ├── source.rs
│ │ └── listener.rs
│ ├── ecs/
│ │ ├── world.rs
│ │ ├── system.rs
│ │ └── component.rs
│ ├── input/
│ │ ├── keyboard.rs
│ │ ├── mouse.rs
│ │ └── gamepad.rs
│ ├── physics/
│ │ ├── rigid_body.rs
│ │ ├── collision.rs
│ │ └── world.rs
│ ├── rendering/
│ │ ├── pipeline.rs
│ │ ├── mesh.rs
│ │ ├── shader.rs
│ │ ├── material.rs
│ │ └── renderer.rs
│ ├── scene/
│ │ ├── node.rs
│ │ ├── transform.rs
│ │ └── graph.rs
│ └── utils/
│ ├── math.rs
│ ├── logging.rs
│ └── timer.rs
└── tests/
├── unit/
│ ├── physics.rs
│ └── rendering.rs
└── integration/
├── scene.rs
└── game_loop.rs代码组织一目了然, 很容易快速定位, 每个文件名都简短精干
leaf_engine/
├── Cargo.toml
├── .gitignore
├── main.rs
├── app_mod.rs
├── asset_loader.rs
├── asset_texture.rs
├── asset_model.rs
├── audio_source.rs
├── audio_listener.rs
├── ecs_world.rs
├── ecs_system.rs
├── ecs_component.rs
├── input_keyboard.rs
├── input_mouse.rs
├── input_gamepad.rs
├── physics_rigid_body.rs
├── physics_collision.rs
├── physics_world.rs
├── rendering_pipeline.rs
├── rendering_mesh.rs
├── rendering_shader.rs
├── rendering_material.rs
├── rendering_renderer.rs
├── scene_node.rs
├── scene_transform.rs
├── scene_graph.rs
├── utils_math.rs
├── utils_logging.rs
├── utils_timer.rs
└── tests/
├── unit_physics.rs
├── unit_rendering.rs
├── integration_scene.rs
└── integration_game_loop.rs所有源文件堆积在一起, 难以快速定位, 每个文件名都相对冗长
Modular Model能够约束系统复杂度¶
组织模块是约束系统复杂度的必要手段.
首先, 系统职责被划分为若干子模块, 较小的模块更为简单, 易于实现且便于复用. 此外, 我们隐藏大部分元素, 仅向外界暴露少量类型, 函数, 类等元素, 本质上这构成了模块的接口. 其他模块只能调用这些接口元素, 从而简化了模块之间的交互. 修改代码时, 只要接口保持不变, 模块内部的修改不会被外界察觉.
通过采用模块化模型, 我们能够尽量降低系统的整体复杂度.
系统的整体复杂度是各个相互交互模块复杂度的乘积, 而每个模块的复杂度则取决于其接口的复杂度. 模块间交互接口越简洁, 系统整体复杂度越低.
不同语言中定义模块的风格对比¶
在不同编程语言中, module的称谓有所不同. 有些语言称之为module, 另一些语言则称为package. 不同语言中定义module的方式也存在差异.
定义模块和引用模块是语言中非常重要的一环, 他和编译器或解释器如何寻找源文件, 如何组织编译成品, 如何解析对模块的引用息息相关. ![[Think 2025-07-16 19.56.46.excalidraw]]
一般而言模块系统有2种风格: 隐式定义和显示定义.
隐式风格¶
隐式定义会将每个源文件或文件路径视为一个module. 因为代码中无显式模块定义, 所以我们称其为隐式风格.\

以rust为例子, 例如user.rs对应user这个module, drawer/mod.rs是一个特殊文件, 对应drawer这个module.
我们还可以在main中定义sub这个子模块.
在这种风格下, 许多语言还支持在单个文件中定义子模块. 譬如以下例子.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21mod math_utils { pub const PI: f64 = 3.14159; pub fn add(a: i32, b: i32) -> i32 { a + b } fn subtract(a: i32, b: i32) -> i32 { a - b } pub struct Point { pub x: f64, pub y: f64, } pub enum Operation { Add, Subtract, } }
这里math_utils就是定义在tool这个module下的子模块
这种风格使源文件的组织即是模块的定义, 直观且易于理解. 使用时, 通过类似import a.b的语句, 编译器或解释器会去寻找对应的源文件, 如a/b.x或a/b/mod.x.
显示风格¶
显示定义需要在源文件中指定module的定义, module结构和文件结构并没有直接的关系.
你可以在M个源文件中定义N个module. 这里module是逻辑上的module, 跟文件和文件结构都没有关系, 两者并不需要一一对应, 因为就算不对应也能够正确编译执行.
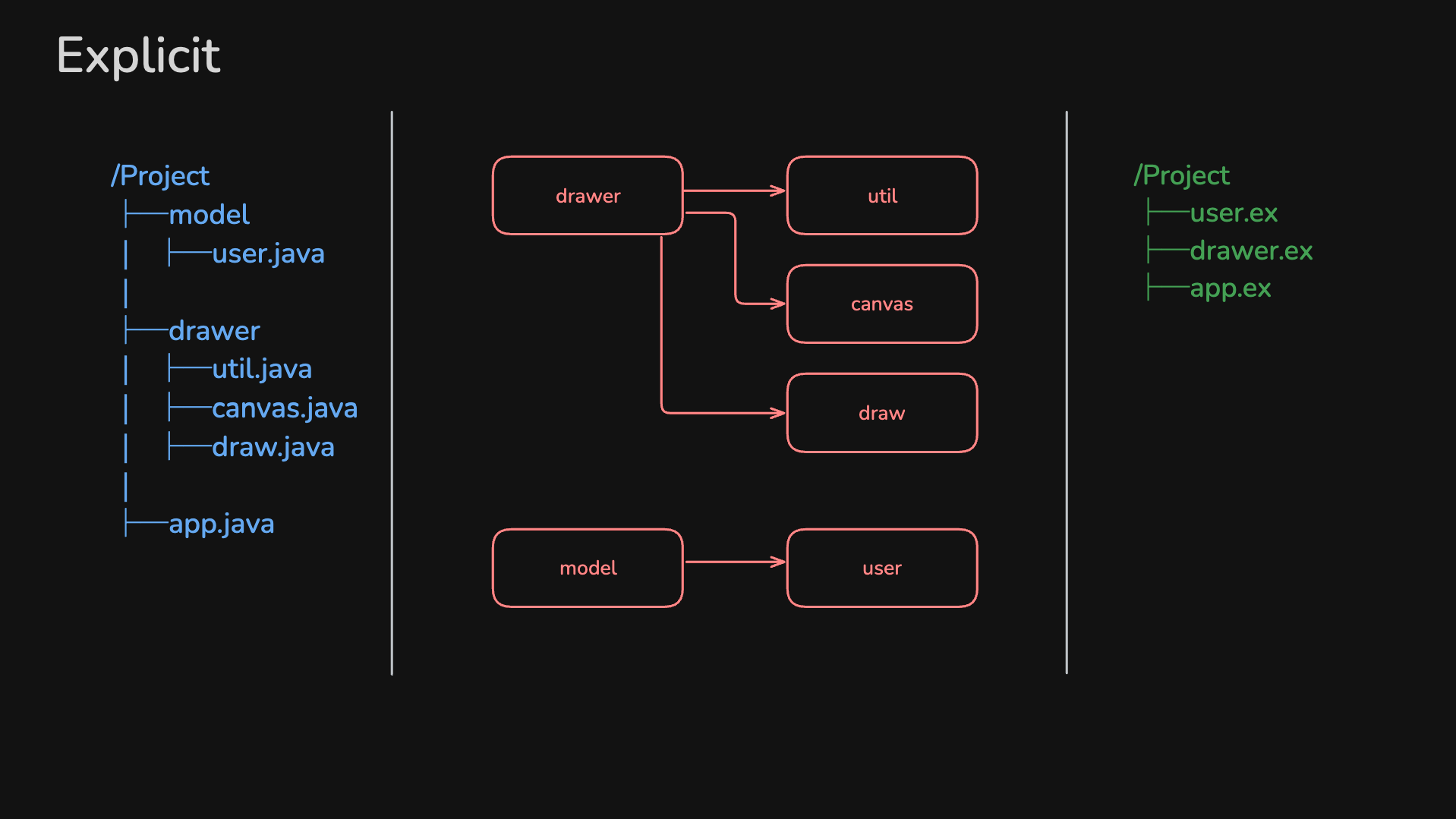
- [左] java项目的文件目录
- [右] elixir项目的文件目录
- 假设两者有相同的模块定义, 即使两者的文件组织结构相差很多, 经过编译, 两者都能形成相同的模块结构[中]
显示风格下有两种具体写法, 分别是: wrapper和tag.
1 2 3 4 5 6 7 8defmodule Greeter do def say_hello(name) do "Hello, #{name}!" end end # Usage example: IO.puts Greeter.say_hello("Alice")
wrapper会定义一个代码块, 然后把内容包在里面.
1 2 3 4 5 6 7package greeter import "fmt" func SayHello(name string) string { return fmt.Sprintf("Hello, %s!", name) }
Program 7:tag会在源文件开头打上package <name>表明该源文件属于哪个module.
1 2 3 4 5 6 7 8 9 10 11 12package main import ( "fmt" "example/greeter" // 这里指定的是文件路径 ) func main() { // 这里的greeter是module名, go强烈建议文件名和module名一一对应 message := greeter.SayHello("Alice") fmt.Println(message) }
无论是哪种写法, 显式风格下, module只存在于编译后的可执行文件或字节码中, 而跟代码没有一一对应关系. 使用的时候通过import a.b这样的语句, 编译器或解释器会从编译后的可执行文件或字节码中找到相应的module.
构建大型项目¶
为什么要提及模块定义这件“小事”呢? 因为它与项目构建息息相关.
通常, 构建过程简单的语言多采用隐式模块定义风格, 而构建过程复杂的语言多为显式定义风格. 其原因在于, 构建项目首先需要定位源文件, 而两者定位源文件的机制完全不同.
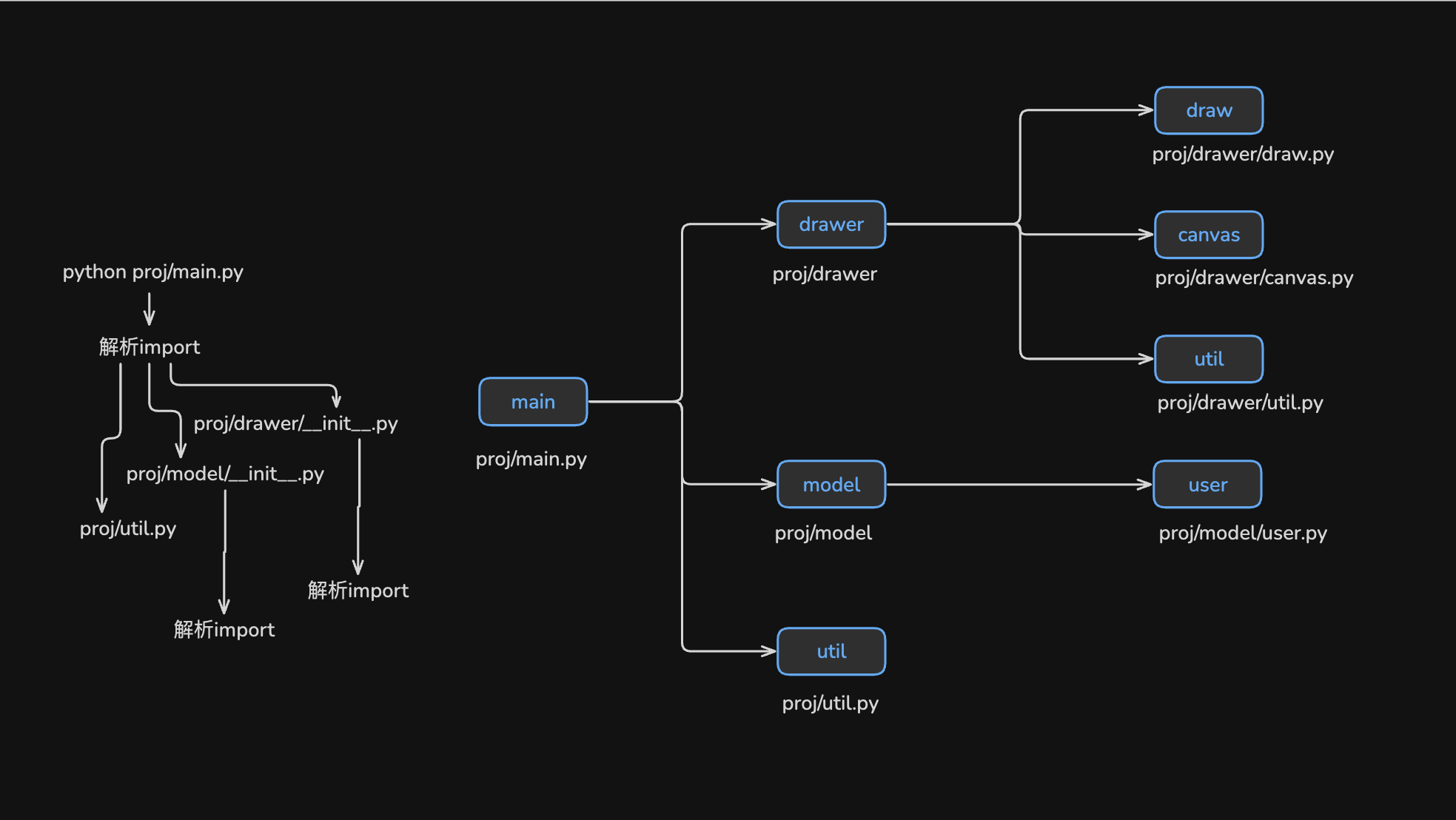
在隐式风格中, 源文件与模块一一对应, 只需解析入口文件引用的模块, 即可找到对应的源文件, 递归此过程便能定位所有源文件.
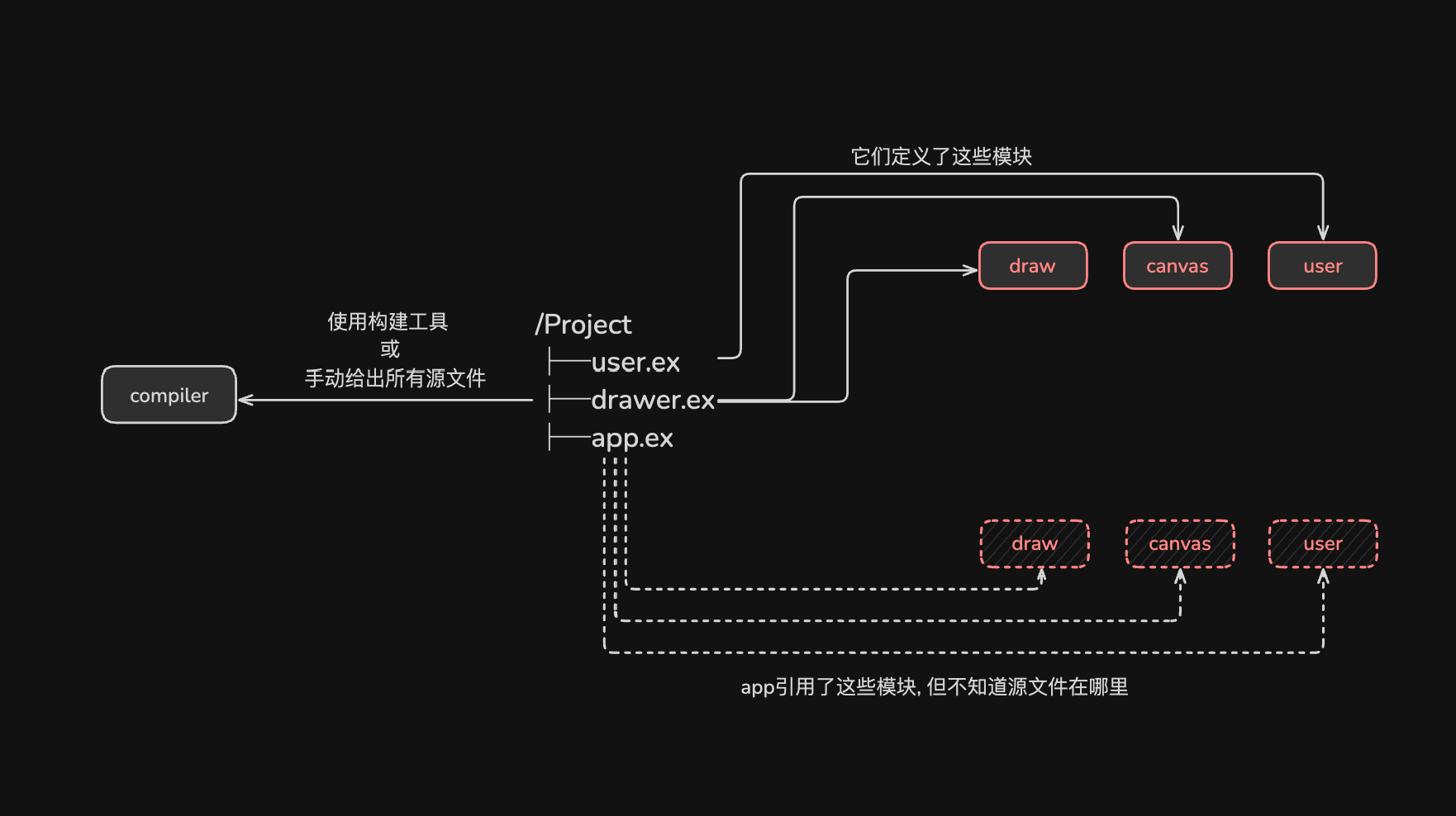
显式定义风格中, 编译器或解释器并不具备自动定位源文件的能力, 通常需要手动指定大量源文件或借助工具扫描整个路径下的所有源文件. 文件的组织方式和嵌套结构对结果无影响, 编译器会根据模块定义来组织字节码文件. 这也是为何这类语言在构建大型项目时通常依赖构建工具, 因为手动管理这些步骤十分繁琐.
不过, 一些显式定义风格的语言采用了巧妙的方案: 在引用模块时, 不使用import a.b, 而是直接用import "file/path", 明确指定模块的源文件路径, 而不是指定引用模块.
如此一来, 编译器即可自动解析所有源文件. Go语言正是采用此方式, 因此go module的构建非常简便, 见上文中 Program 7 和 Program 8.
怎么快速上手模块系统¶
想要快速上手, 我们需要掌握以下几个要点.
首先, 通过语法你可以快速判断当前语言采用的是哪种模块定义风格.
如果是显式风格, 可以直接搜索“语言+toolchain”或“语言+build tool”, 了解如何使用构建工具创建和构建项目. 隐式风格, 则看看怎编译或运行入口文件.
其次, 无论何种风格, 每个项目都会有项目根目录.
- 显式风格中的构建工具会从根目录下的某个子目录开始搜索源文件
- 隐式风格的编译器或解释器则将入口文件所在路径视为根目录, 从根目录开始查找对应模块的源文件.
最后, 无论何种风格, 最佳实践都是让代码结构与模块结构一一对应. 隐式风格强制这一点, 而采用显式风格的语言则通过范式来要求, 且几乎没有例外.
例外¶
除开古早的语言和冷门的语言, 也有少部份语言目前是不支持module的, 譬如c/c++(c++这个特性未来会有). 另外一些语言定义了一种完全不同的module体系, 譬如swift, 这里就不再展开了.
Module和object的关系¶
为什么modular model会和object扯上关系?
如果仔细观察, 我们会发现, module和object在使用上的唯一区别是, module是个单例对象, 而且其中一般没有状态变量, 除此之外module能够进行封装, 并对外提供自己定义的接口. module提供了object功能的子集.

- [左] 作为module的stack仅暴露一组无状态函数, 它不会创建实例
- [中] 作为class的stack也仅暴露一组无状态函数, 跟module类似
- [右] 作为object的stack"也可以"暴露一组方法, 同时在外部管理数据, 虽然我们一般不会这么用, object能够提供更加强大的功能
如何用好module¶
什么时候使用module呢? 如果没有特殊要求, 最好处处使用.
一般简单的feature用起来门道多, 复杂的feature则正相反. modular model很简单, 只不过是把同类的元素放在一起, 提升内聚, 对外提供定义好的接口, 降低系统复杂度, 但如何用好module是一门学问.
Group by Feature VS Group by Subject¶
首先, 如何整理模块?
把相关的元素整理到模块里, 方法有很多, 最常见的有两种方式
group by subject: 按照元素类别来整理group by feature: 按照功能来整理
以web server项目为例, 按照java中的命名方式, 一般有model, service, controller这几类对象.
- model是负责承载数据的类
- service负责提供业务逻辑的类
- controller负责注册url以及处理请求的具体逻辑
如果服务有两个api, 一共提供User的增删改查, 一个提供Product的增删改查.

- group by subject就是把User和Product的model放在一个模块中, 两者的service放在一个模块中, 两者的controller放在一个模块中, 所有的util/helper放在一个模块中.
- group by feature则按照不同的feature来组织, User相关的所有内容放在User模块, 其中有User相关的model, service, controller, util, 分别放在相应的子模块. 同理Product.
研发职责分配¶

此时每个模块的大小都膨胀了数倍, 每位开发者都需要修改所有的模块才能完成新功能, 代码冲突频繁发生, 代码理解困难, 一个功能的代码散落在不同的模块中
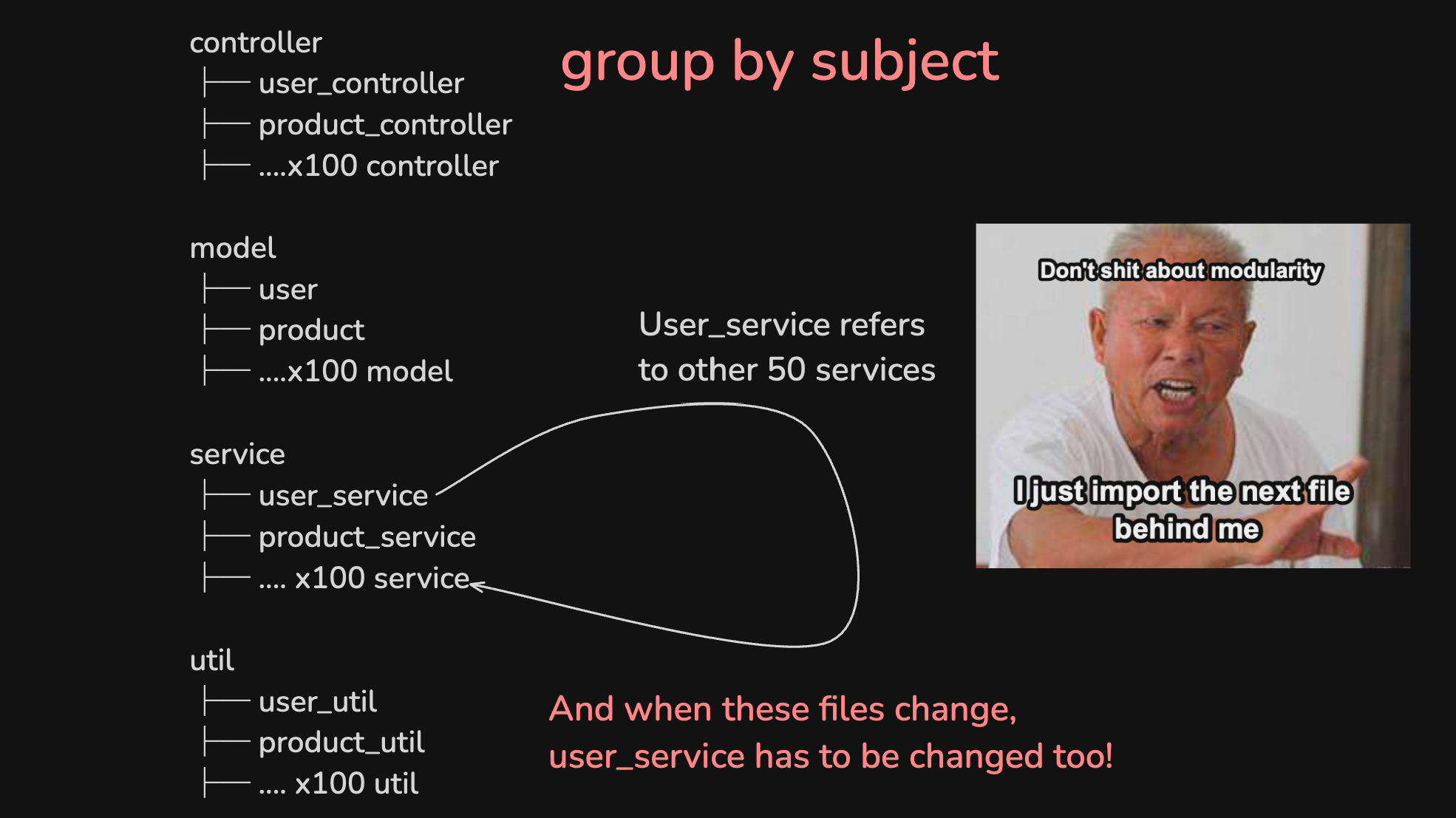
在这种模块组织下, 总会有开发者会引用"同一模块下"的"兄弟模块", 譬如user_service去引用其他service来完成功能🥶.
毕竟引用同一个模块中的子模块, 并没有违反任何原则, 对吧?
对...还真是...
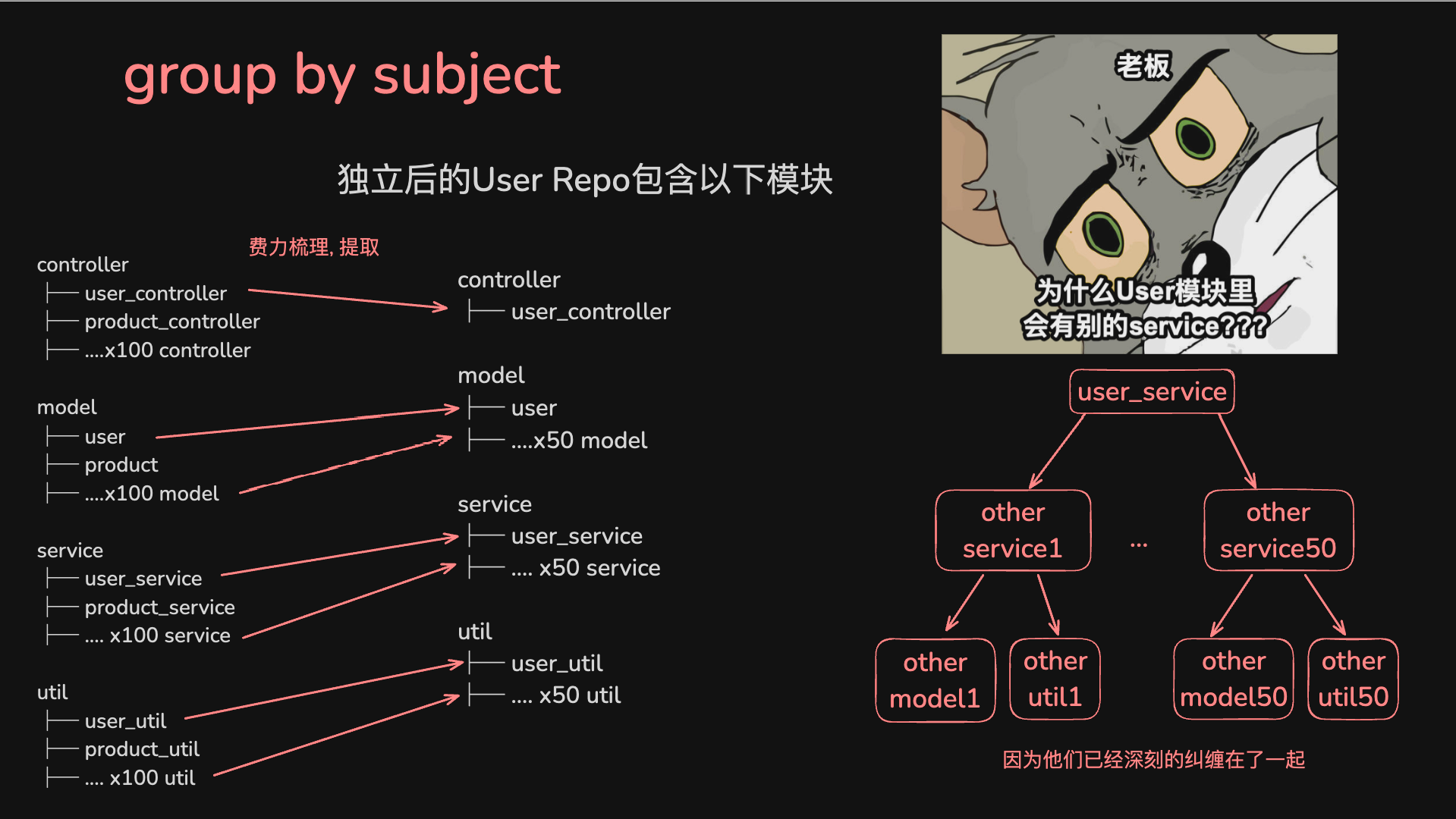
经过漫长且痛苦的依赖梳理后, 终于把User提出来了, 但附带了一堆其他模块的文件. 此时老板开始咆哮:
- 为什么User模块里需要包含其他模块的service和model??
- 这些冗余的service和model怎么管理? 他们是随着User repo升级还是随着原来的repo升级? 谁来管理他们?


模块大小没有改变, 但是增加了100个新模块. 每个开发者都被分配若干模块进行维护, 代码冲突鲜有发生, 因为模块小, 理解起来也容易, 一个功能一个模块.

简单把User模块从原repo中移到新repo中, 几乎不费功夫, User很干净, 几乎没有除了util和三方库之外的其他依赖.

group by subject适合简单人少的短期项目, 因为在这种项目中工作并不需要对feature有理解, 也不需要费力去组织模块. 但是当项目逐渐变大, 人员逐渐变多, group by subject的劣势就非常明显了.
Group by feature是业界比较推荐的代码组织方式, 适合长期, 大规模的项目. 但业务在演进, feature本身也在不断改变. 模块组织需要对应业务本身的演进. 所以在业务发生改变的时候, 需要及时重构, 调整模块组织. 否则就会欠下技术债.
如何评价模块质量¶
评价模块的interface的质量¶
是否履行单一职责, 处理同一类或者同一个范畴的问题? 如果不符合单一职责, 模块组织就不算合格.api设计是否简洁有扩展性? 函数不应该设计的过于具体, 否则api中会有多个非常类似的api, 这不够简洁. 函数不应该设计的过于抽象, 过于抽象就能够承载多于一个职责, 使用起来也困难.api中每个函数是否有足够的doc说明其用途? 这里doc不应该说明函数的实现细节, 而应该说明函数的意图和行为.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30from typing import Any # 过于抽象的设计, 不符合单一职责 def process_data(input1, input2, dubious_switch, flag=True, mode=0, callback=None, config=None, *args, **kwargs): ... # 不够简洁, 过于具体, 扩展性不足 def send_welcome_email_to_new_user(user_id: str) -> bool: ... def send_password_reset_email_to_user(user_id: str) -> bool: ... def send_order_confirmation_email_to_customer(user_id: str, order_id: str) -> bool: ... def send_shipping_notification_email_to_customer(user_id: str, tracking_id: str) -> bool: ... def send_promotion_email_to_subscriber(user_id: str, promo_code: str) -> bool: ... # 单一职责, 简洁可扩展, 有足够多的doc说明用途 def send_email(template_type: "EmailTemplate", recipient_id: str, context: dict[str, Any]) -> "Email": """ @param template_type: email模板 @param recipient_id: 收信人id @param context: 上下文信息 """ ...
评价模块的独立性¶
我们把独立性分为几档.
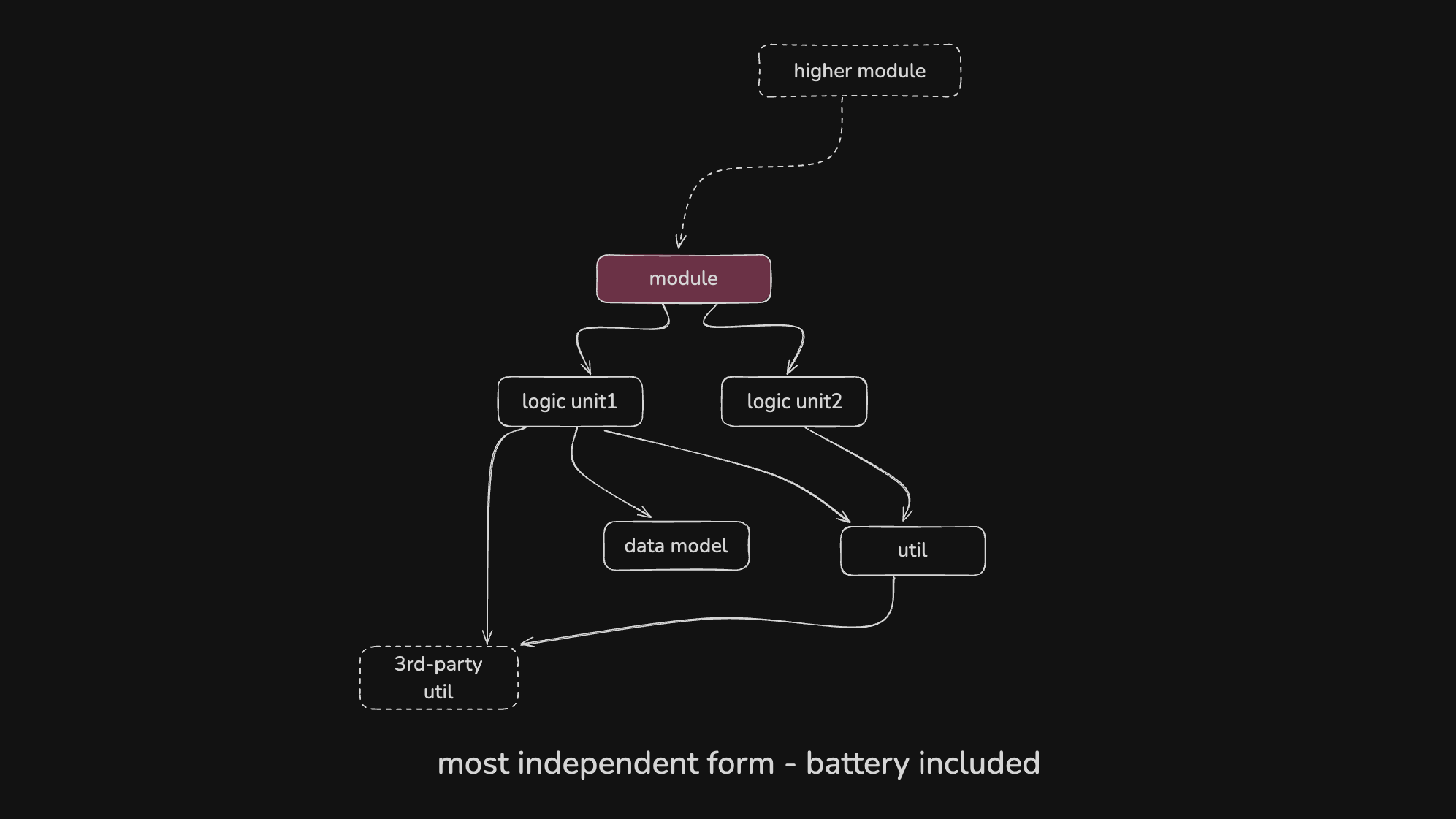
拥有最佳独立性的模块, 只依赖内部子模块和三方模块, 不依赖其他模块.
这样的模块甚至可以独立发布.
一般业务无关的通用的util会整理成这种模块. 有必要的话model也可以整理成这样的模块进行内部发布.
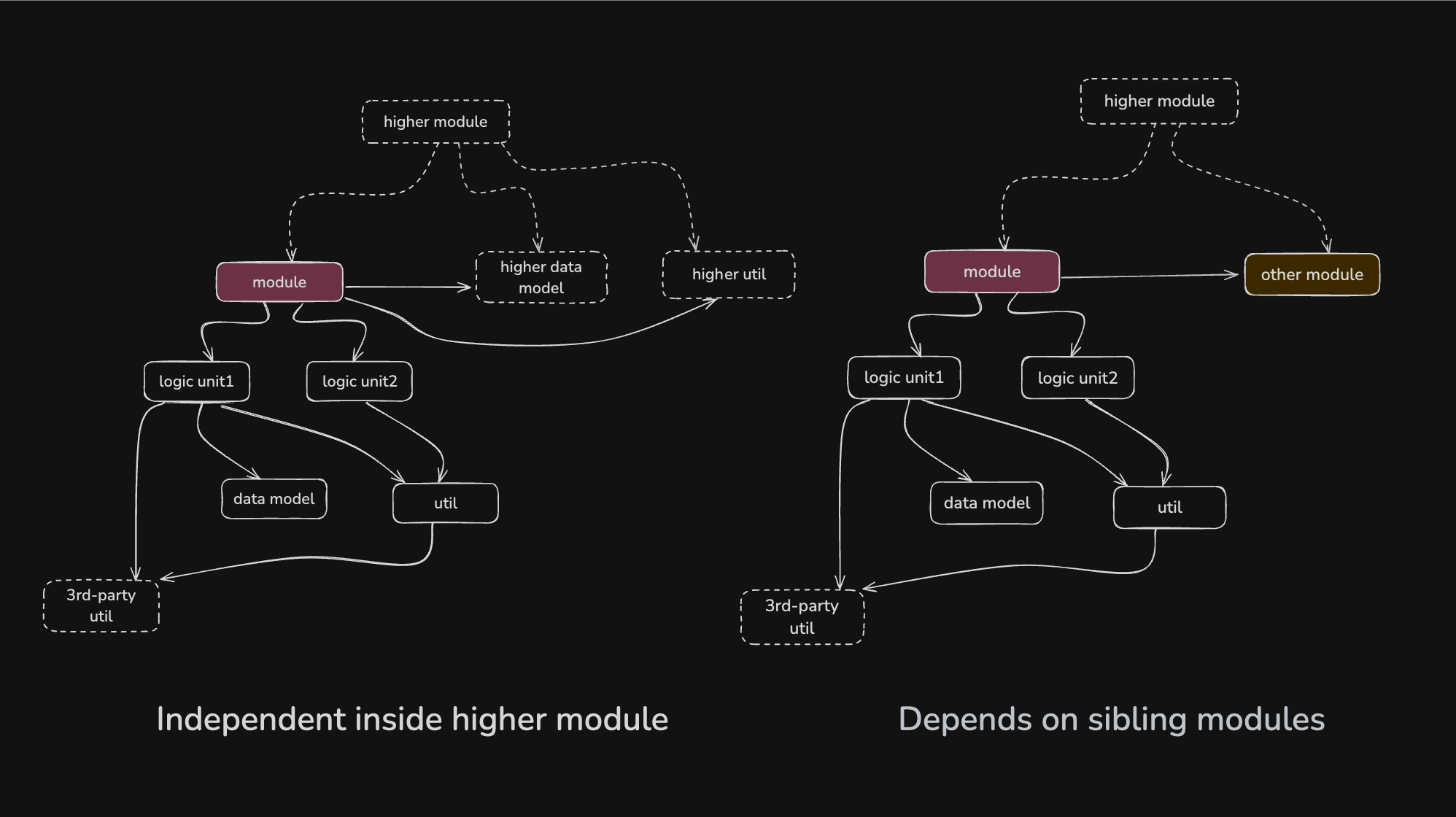
如果一个模块还依赖自己的兄弟模块, 独立性就弱一些, 但在其父模块中, 他仍然保持了一定的灵活性.
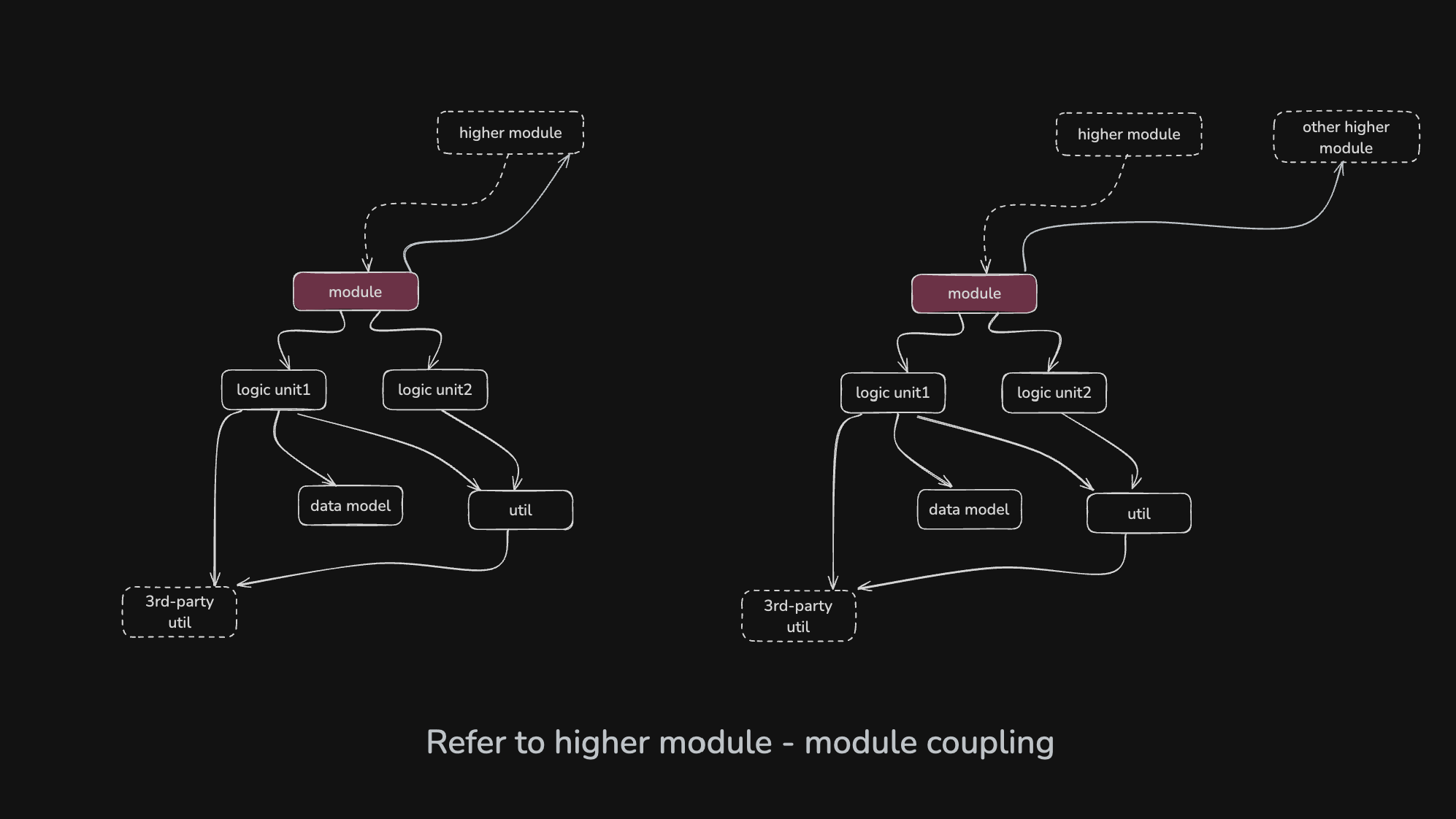
如果一个模块反过来依赖了父模块, 抑或其他同级或更高的模块, 那就在模块依赖树中引入了环. 环涉及到的模块会全部耦合在一起. 一般出现这种情况是对代码库的巨大破坏.
两种常见情况的处理¶
下面再说两个常见的状况.
拿来主义¶
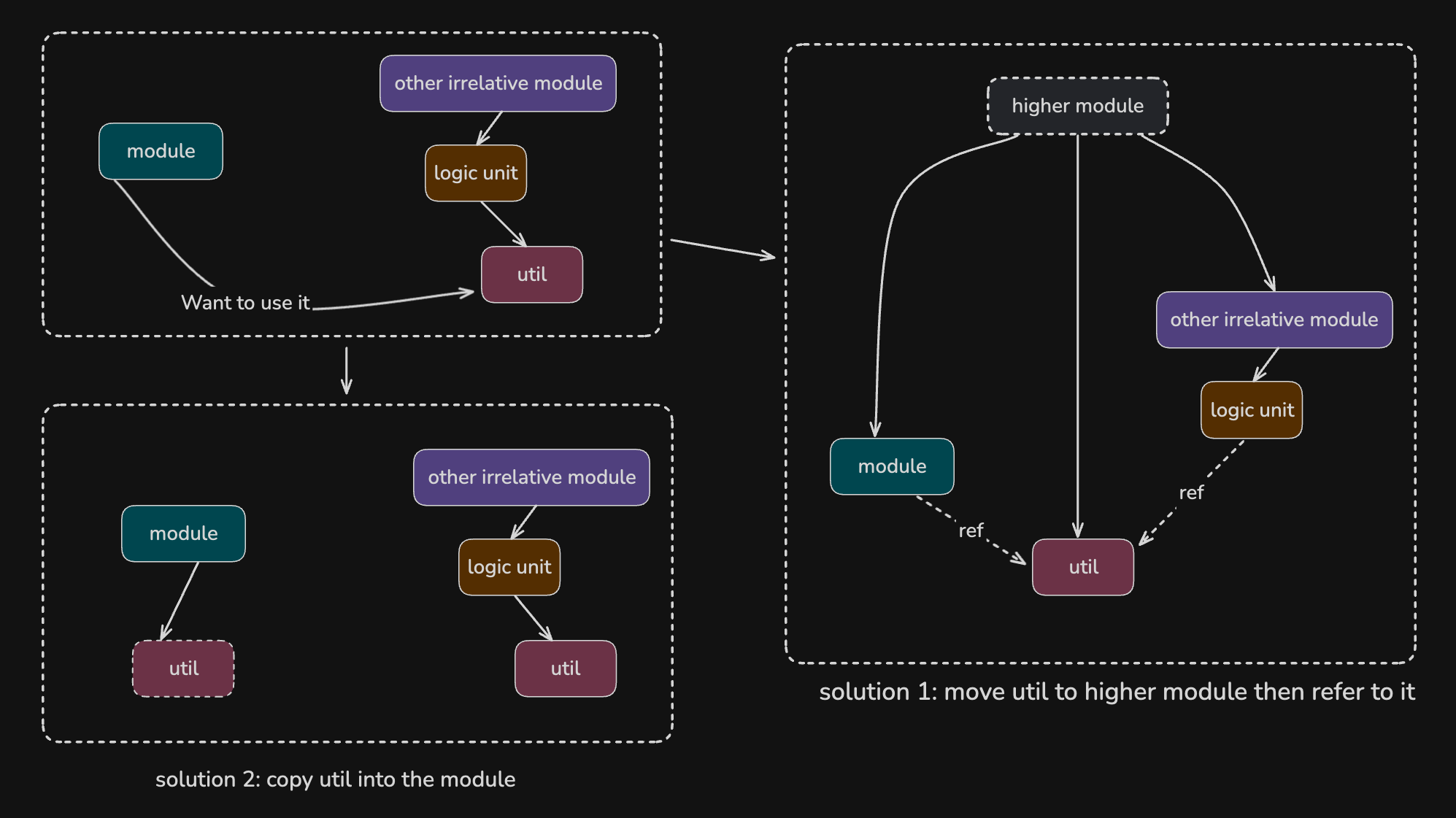
有时我们会发现在实现自己模块的时候, 其他模块有一些私有的util特别方便, 想要拿来主义, 应该怎么做呢? 有两种办法.
我们可以将这个私有的util提升到更高层级的module下. 这样, 对方module和我的module都能引用这个util. 不过, 首先util必须适合被暴露, 具备较强的通用性且无副作用. 因为一旦提取出来, 其他模块也会引用, 绝对不可能再放回去.直接复制一份util到自己的模块下. 有人会反对, 认为这样增加了代码冗余, 这确实如此,但相比代码冗余, 模块化更为重要. 当两份util需要由两个团队维护, 且这两个团队缺乏共同演化的愿景时, 这种做法是合适的. 当然, 这种情况并不常见. 如果你发现有大量内容需要搬到自己的模块下, 应该反思自己模块的存在必要性.
封装三方库¶
有时候, 我们会发现一些第三方模块或库需要被大量使用, 这些第三方模块或库的重要性极高, 以至于几乎每个模块都依赖它们, 例如某些特殊计算模块, 特定领域的概念和util, 或数据库等常用功能.
在引入它们之前, 需要做出抉择: 是直接使用这些库, 还是重新封装一套相同API的模块, 并将功能代理给它们?
以下是一个数据库三方库的示例.
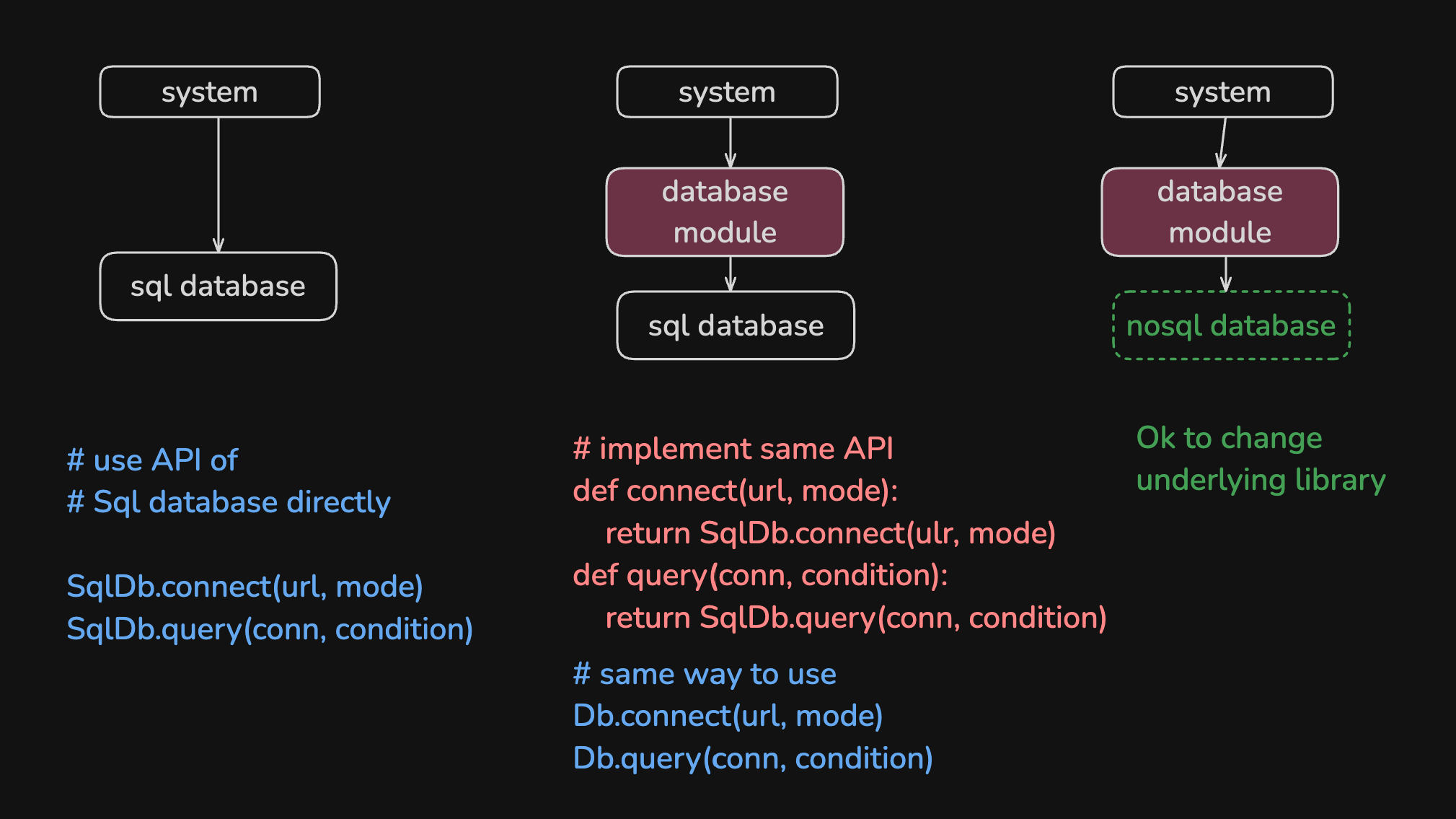
- span style="color:blue"[左] 直接使用三方库, 直接依赖三方库API
- [中] 封装一套相同的API并把功能代理给三方库, 使用和直接依赖三方库API没有区别
- [右] 即使三方库升级后改变了API, 甚至直接替换三方库也不会影响我方代码, 等于我们隔离了三方库和我方代码的依赖关系, 他们都依赖我方API
如果引入的库API和性能绝对稳定, 且我们的需求也非常稳定, 不需要在第三方库基础上进行扩展, 那么直接使用它们是合理的.
但若这些库的API仍在变化, 性能不稳定, 甚至存在一些不适合我们需求的边缘情况, 同时我们还需要扩展这些API, 则推荐封装自己的模块, 提供一套完全相同的API, 并代理给第三方库.
如此一来, 任何改动(甚至切换底层第三方库这种改动), 也只需修改自己的API下的实现, 其他调用代码无需变更. 这正是应用依赖反转原则的一个实际场景.